
In my last post about Computational Photography we ended on an idea that mass photography is slowly moving towards ‘improving’ our reality. Instagram masks replace gloomy faces, beautiful clouds are glued to the grey sky, and color filters make our boring life look a little better than our neighbor's. And that's crucial.
That's what we call Augmented Reality or AR — when we mix our reality with virtual objects up to a point where the former is completely replaced.
AR is passing through its valley of disappointment right now. Hipsters temporarily forgot about it, nonsense startups went out of business, and the smart guys have latched on to B2B contracts, doing their innovations away from the eyes of the general public.
Meanwhile, real progress is happening where no one is looking. We only hear about Pokemon Go and Apple Glasses, while the same technologies are actively developing and helping us in other areas — self-driving cars, arctic glacier analysis and even their majesty robotic vacuum cleaners.
The AR is like homework that nobody wants to do because we found so many other interesting toys around. It's a good time to take a break and get things sorted out without all the typical hype and bullshit.
In the course of the story, I will refer you to some good 💎 articles, highlighting them with silly emojis. Usually, they are either primary sources of information, or recommended readings for those crazy ones who want to dig deeper.
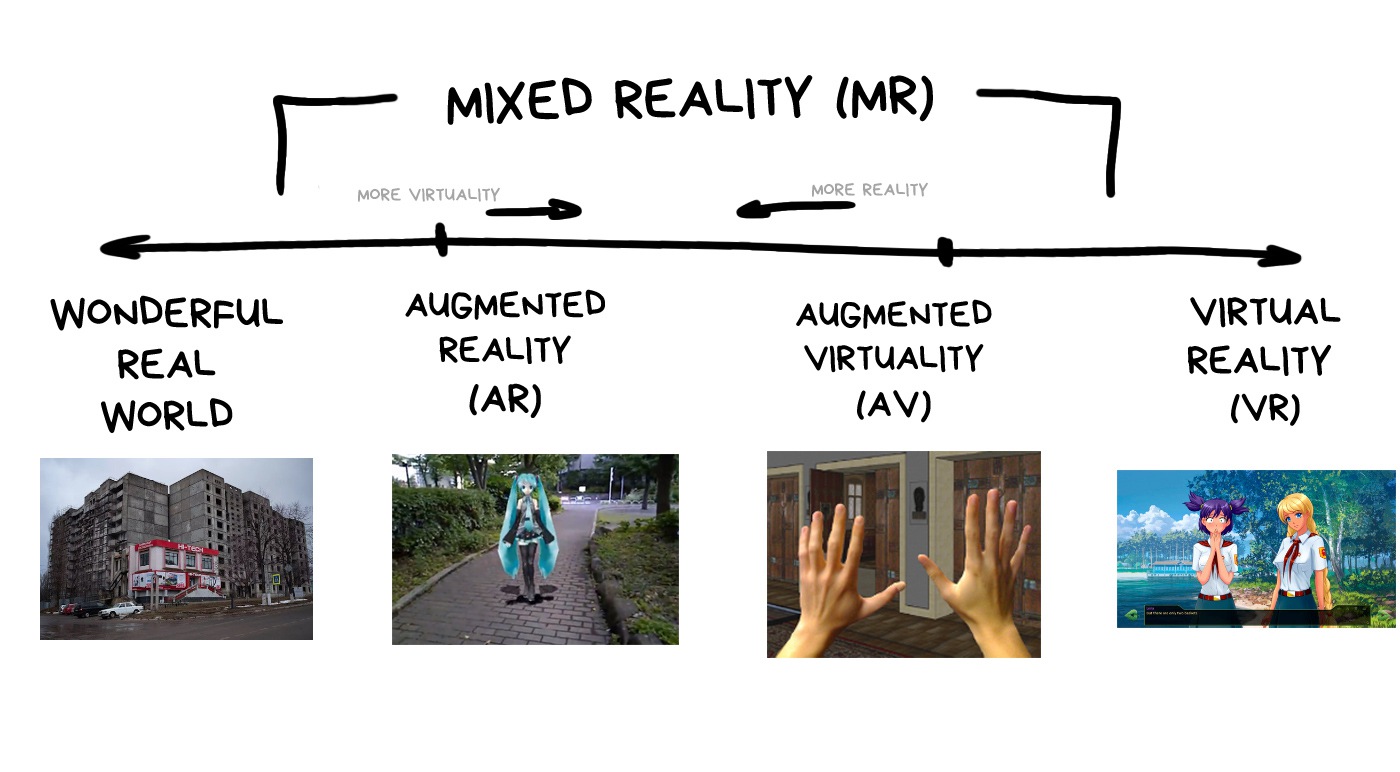
Let's start with a quick look at the terms. What is augmented reality and how does it differ from virtual reality and why are they so often mixed together?
I'm gonna use the classical definition, according to which it is simply a matter of a different degree of mixing of the real and the virtual worlds.
For example, the video game world where you rescue a beautiful princess while riding a tyrannosaurus is a virtual reality.
The world where you go to the Walmart to buy a six-pack of beers to watch Netflix alone for the whole weekend is an objective reality.
Augmented is somewhere in between.
Today, the technical difference between augmented and virtual realities is not as big as it may seem. Modern VR and AR helmets use similar methods of tracking in space, and some of them even begin to mix realities.
For instance, Oculus Quest switches your game to the view from the cameras if you suddenly move out of the gaming area and are in danger of stubbing your toe on the sofa leg.
In this post, I will constantly mix AR, VR, and MR. Because technology.
💎 The Ultimate VR, AR, MR Guide
Let's throw away esoteric options like making holograms on artificial fog, projecting an image on a physical object, fast rotation of LEDs and other cyberpunk lenses.
It's nice to dream about, sometimes it even works, but technical progress is not there yet.
Let's look at the real types of screens that are used in AR/VR helmets right now. The information is relevant as of 2020, but given the dynamic, this will last maybe another two-three years.
So, there are two big fandoms now: video and optical displays. In the first one you see the video from the cameras; in the second, you look at reality with a hologram cleverly placed over it.
Both variants have their pros and cons.

Turn the camera on your phone and hold the screen to your eyes. Congratulations, you are using the video display.
Most often it looks like a VR helmet with multiple cameras. The cameras capture the world around you and transmit the processed video to your eye. You can't see the real world, it's just screens in front of your eyes.
At this stage of technology, video displays have the biggest wow factor for an average person. That's why everyone loves showing them in presentations and video clips.
Here are the popular ones:

✅ Simpler and cheaper. No additional cameras are needed for position-tracking plus we have many technologies ready for working with video.
✅ Tracking and illusion of reality are better. The picture doesn't fall apart when you sneeze or move your glasses.
✅ Less problems with calibration. Anyone can put on a helmet and start using it without adjusting anything.
💩 Video quality is lower than reality. As of now, we don't have screens that would have both satisfactory resolution and FPS.
💩 The delay can literally kill you. Imagine driving in a helmet like that, and it freezes for a second. Or using a buzz saw. Ouch.
💩 Nausea. Literally.
💩 Only one focal plane. You need extra hacks to analyze when the user is looking right in front of her or 100 metres away.
💩 Good bandwidth is required. Sending pictures to each eye in more than 4K resolution is not easy.
All the cool kids already have eye position tracking. Two small cameras look at your pupils and determine which part of the virtual world you are looking at to adjust the focal length.
One of the promising tricks on the peculiarity of our vision. As it turned out, our brain is quite lazy and perceives only a small part of the "frame" in high resolution, while everything around can be ten times blurred, — it doesn’t give a shit.
When you're reading this text, your brain probably ignores just about everything around the screen. It just doesn't care.
Today Foveated Rendering is mostly shown at exhibitions, but soon it will reach existing devices.
🎥 Improving VR with NVIDIA’s Foveated Rendering

It’s also called True AR in some sources.
You look at the world through ordinary glasses that put an additional picture on top of reality. They use semi-transparent mirrors, prisms, holographic film, waveguides, or whatever else is invented in your century.
Owners of newer car makes may have seen the windshield projection with current speed and directions — that is it. Some motorcycle helmets have them too.
But the most famous optical AR glasses are, of course, HoloLens, Google Glass and Magic Leap.

✅ The user doesn’t get out of reality. This adds safety, reduces delays, increases social acceptability, etc. You can even drive a car, play squash and do other important work.
✅ You don't have to reinvent human vision. No hacks for focus and brightness control. Not having nausea is also a big advantage. Or not.
✅ Energy saving and hibernation. Glasses can turn off and wake up when needed without turning reality into a black square.
💩 Small field of view (FOV). The picture takes up an average of 35° from the eye’s usual ~200° (okay, 130-150° for working areas).
💩 They require individual calibration. The picture is so tiny that it needs to be projected directly onto the pupil. That's why some gadgets are even tailor-made for a specific user. Good luck selling it on E-Bay.
💩 Very sensitive. Even a fallen hair on the glasses’ lens can break the whole picture.
💩 Brightness. Still disgusting even in top models.
💩 Flickers. Waveguides and polarization grids create a lot of glare and reflections. It's very annoying to anyone who has tried, for example, Hololens.
👉 Google Glass and hundreds of its clones.
An ordinary projector (LCoS) shines light on a prism that reflects this whole thing into your eye. It's cheap and cheerful. Like a teleprompter.
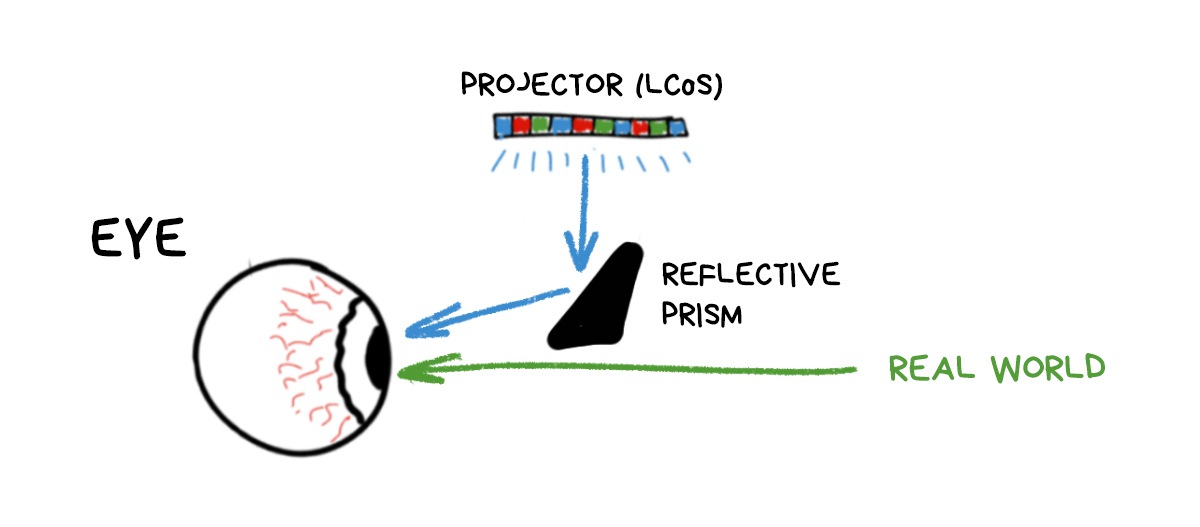
The only problem is that the image always turns out small, because you can’t have a prism the size of half of your head. Or can you? 🤔
👉 ODG, Rokid Glass, Nreal Light.
The implementation of the ‘let's somehow put huge prisms on the user’s face’ idea. But, instead of the prisms, they actually made a translucent mirror and huge reflective half-spheres, which reminded someone of, uh, birdbath tubs, so they were called birdbaths.
I'm sure it's something British.
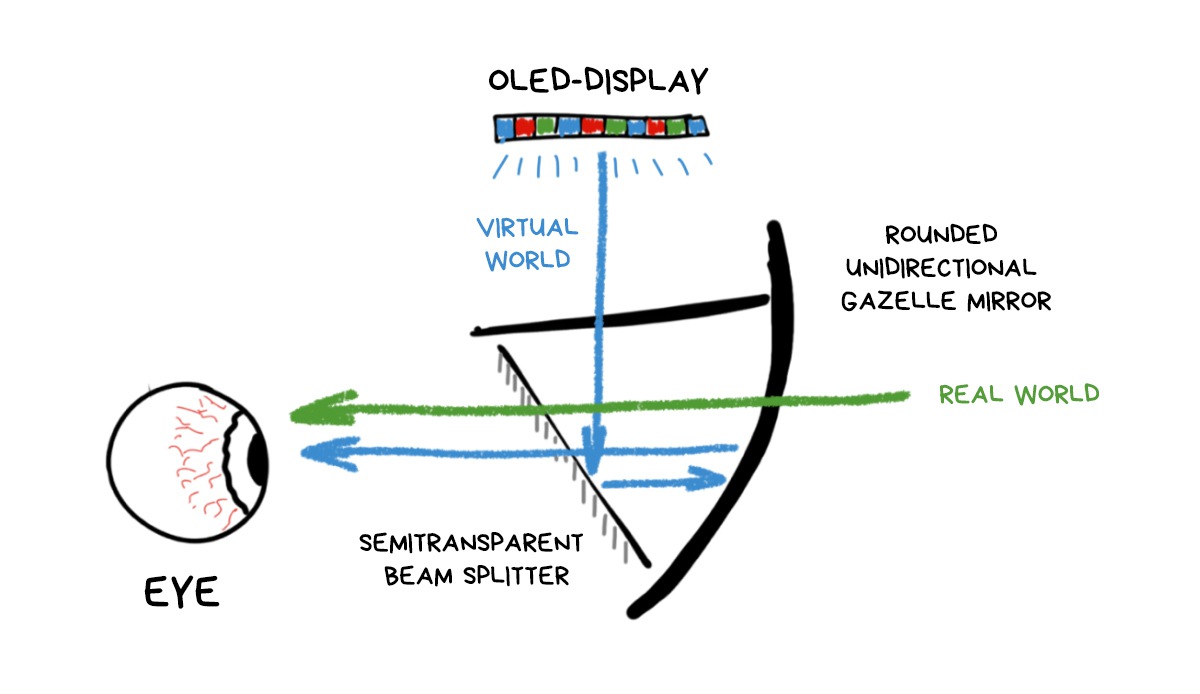
Their great advantage was that you could use it with any OLED display (like your phone has), without any special projector. The rest, unfortunately, were the downsides.
Now, birdbath glasses are almost all extinct. Only plastic copies are sold on Aliexpress, allowing you to insert a phone in them and feel like you've lost thirty bucks on the impulsive online shopping again.
💎 How Augmented Reality Headsets Work: Diving into Differentrent Optical Designs.

👉 Hololens, Magic Leap, Rokid Vision, Vuzix Blade.
Today, waveguides are considered the most useful technology.
The waveguides are exactly what it says on the tin — they guide one beam (pixel) of light from the source along a tricky trajectory inside the lens of your glasses. Then it comes out of the right place of the glass into your eye to form a picture there.
It uses the same principles as the fiber optic cables (where the internet comes from). Light enters from one end and leaves from the other. If you look at the fiberglass wire from the side, it is semi-transparent and you will not see any light inside.
Same for the waveguides: it’s a bunch of channels for light and prisms for reflecting them into the eye. Microsoft's HoloLens presentation proudly states that it "directs each photon of light to the right place in the eye", that sounds bold and cool. Until you try it.
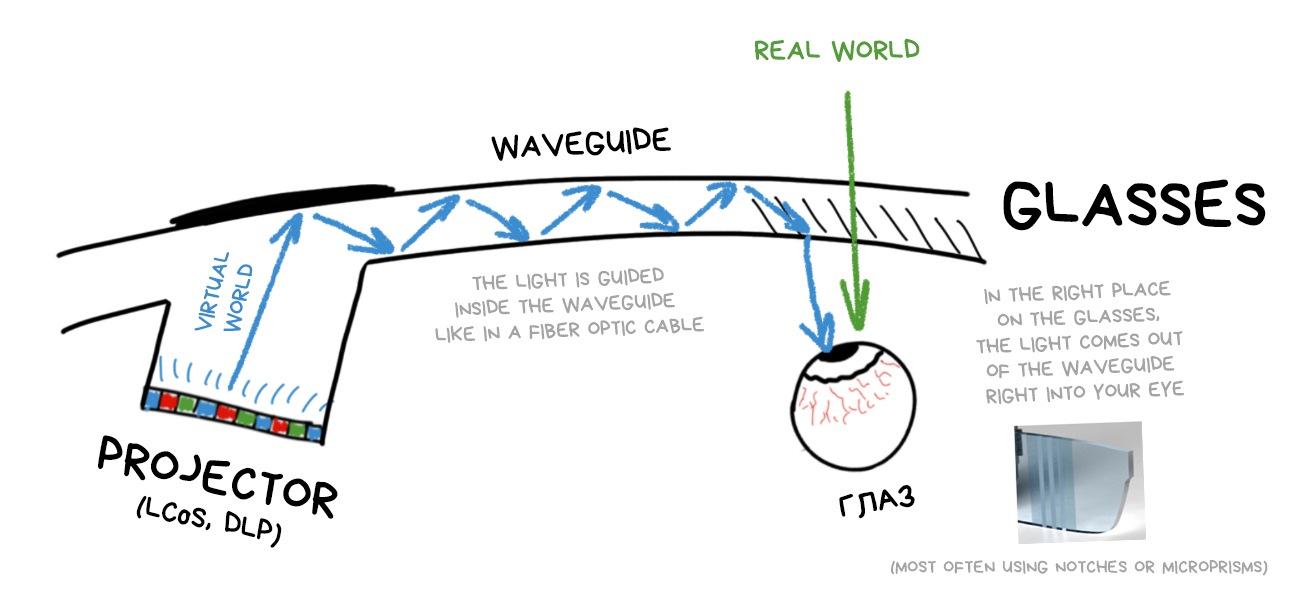
The most important problem of the waveguides at the moment: they're very difficult to grow. The rejection rate at the factories is huge, there is no repeatability, that's why these helmets are so expensive. You just throw away five defective helmets for every good one.
💎 Understanding Waveguide: The Key Technology for AR Near-eye Display
👉 North Focals, Bosch Sensortec, Intel Vaunt ☠️.
Waveguides are our present, but LBS seems to be our future.
It's very similar to the principle of old cathode-ray tube TVs. There, a bundle of electrons, deflected by a magnetic field, drew strips on the screen. The same principle is used here. A thin beam of light is deflected by a miniature moving MEMS-mirror and shines into the right place of a special film on your glasses to build an image. Laser beam is basically the size of a pixel, but it moves so fast it feels like a continuous picture.
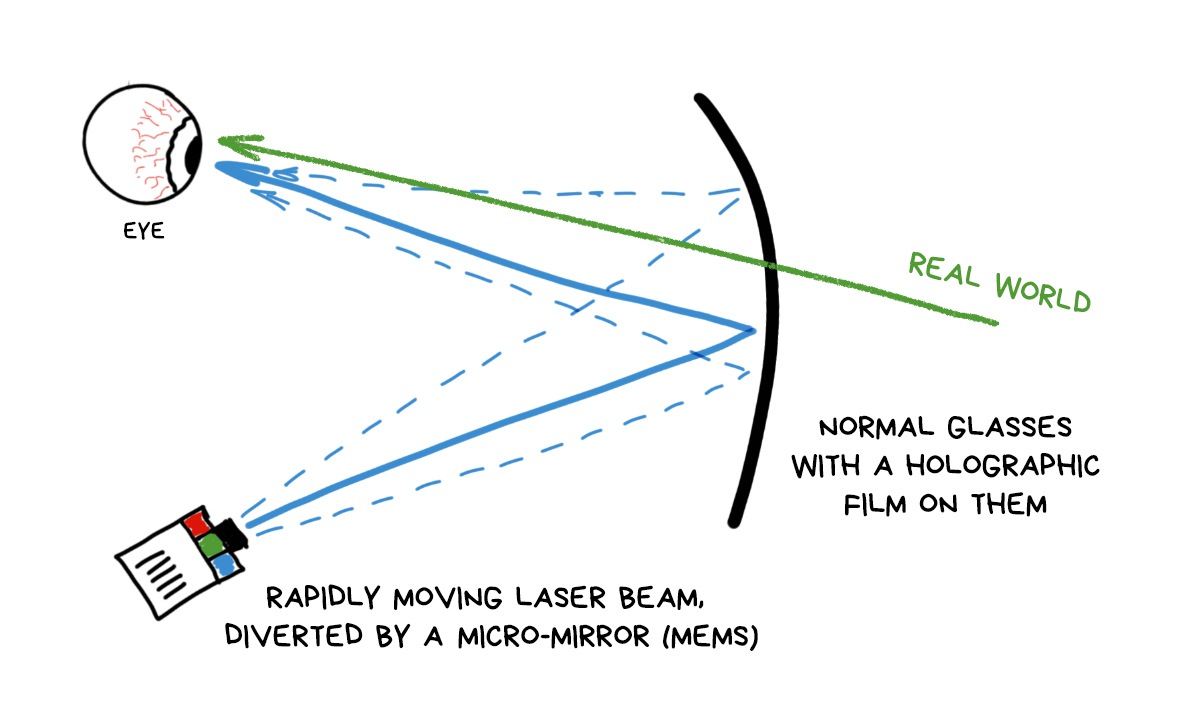
No expensive waveguides, no bulky mirrors required. Take any glasses, glue the holo-tape on it, calibrate the laser and go. So far, these gadgets have just started to appear and they're having big problems with the picture quality. Some of them are even monochrome.
Their simplicity of use and projected low cost means Apple glasses can be exactly this.

Their only problem is that there is no AR so far. It's just glasses with notifications.
In terms of consumer characteristics, video displays are winning today. The picture in them looks good right away, they require a minimum of sensors and almost no calibration. Like a regular VR helmet — put on and go.
That's why they are most often taken for B2C video solutions. Today, you can turn any smartphone into these.
However, there are always guys from Boeing and Lockheed Martin with their own unique problems. For example, their planes have thousands of wires and each requires at least five people to verify it's connected right.
Saving five seconds per wire will save a thousand man hours and a million green presidents for them.
HoloLens quickly saw the niche for Magic Leap. They made a helmet where you can say "show the AB713H-21 wire" and it shows you which holes to drill and which connections to check.
Video-displays had no chance here.
There is even an inside joke: AR glasses always start like RayBan, but end up like HoloLens.

Let's move on to the algorithms.
The first task we need to solve in AR/VR helmet is to determine the position of ourselves by six degrees of freedom (three axes of rotation and three movement directions). In short, it's called tracking.
There is a chicken and egg problem here. To calculate our exact position in space, we need to know the dimensions of this space, and to calculate them, it would be really nice to know our position.
The problem was usually worked around. First, we had some grandfather's methods.

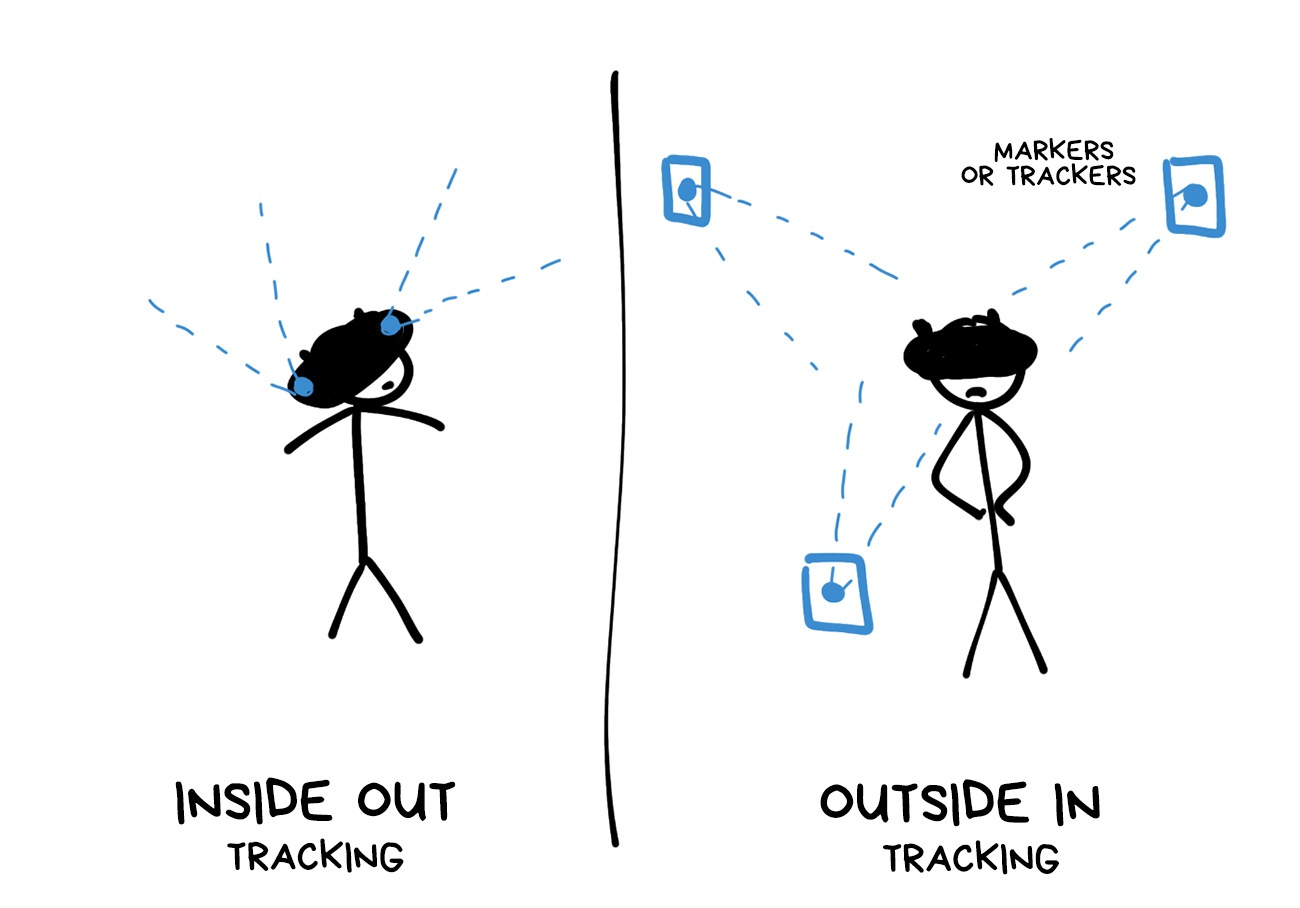
Tracking using specially printed picture markers was available even on my old Nokia on Simbian. Today it can only surprise your grandmother. Although, in some use-cases, it's still ahead of the rest of the hipster methods. For example, if you're making AR board games or museum installations.
Marker approach was followed by tracking on external sensors, where you need to place several cameras (like for Oculus Rift) or passive infrared beacons (like for HTC Vive) to calculate the player's position in the room by them.
A friend of mine once moved his wardrobe to get a gold rank in the Beat Saber. That's what I call a UX!
The real solution came with the SLAM.
Imagine you're in the middle of a city you don't know, and you've been told to draw a map of it. What will you do?
Most likely, you’ll start wandering the streets, marking memorable objects like buildings, monuments and street names. At the same time, you’ll be drawing the streets and buildings on the map, and correct them if needed.
In order not to get lost, you can also take pictures of some streets on your phone, so that you know that you've already passed this intersection for sure.
SLAM works in exactly the same way.
It finds the reference points around, determines its position relative to them, then builds its internal world map, constantly correcting it.
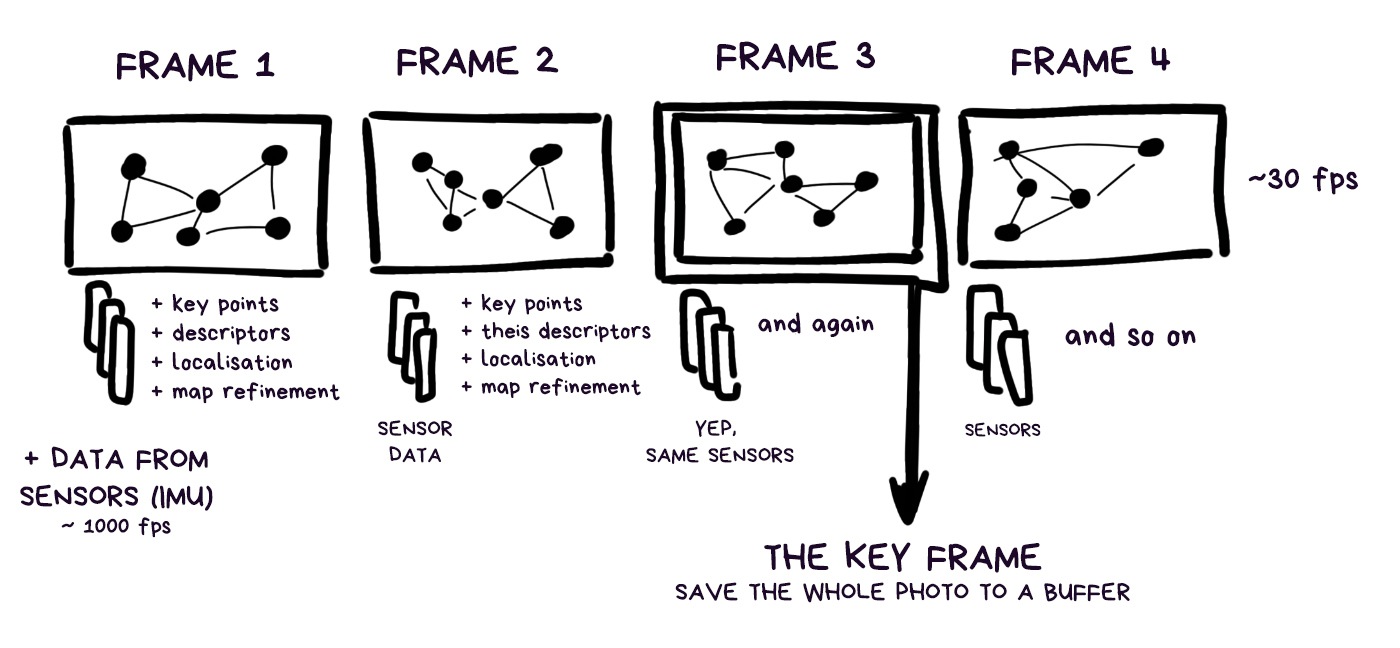
There are ‘photos of intersections’ here, too. They're called Key Frames and are used in the same way — when the robot gets lost, it can pull a bunch of these photos out of memory and analyze if it’s been on this street or not, using any useful key points.
SLAM is not the one algorithm. It’s a common name for any algorithms that calculate the map and the position on it, as if ‘inside’ the observer. There are a lot of them.
SLAM is used in AR/VR helmets, in self-driving cars, and even in your vacuum cleaner robot
Every large company has its own patented SLAM, which they don't share with others, but we all understand that all they are is just more vendor-made sensor support and hardware calibration. Fundamentally, they're the same as I’ve described here.
For example, here's Patent of Google where they tell us the same story. Apple has its own VIO and even a lecture from WWDC with some nice pictures. Take a look.
In the Open Source we have an ORB-SLAM2 algorithm, which is good to train beginners and may be useful for some pet projects.
I will often use similar words like Tracking, Localization, Odometrics, SLAM, etc. People who are passionate about the subject see them as dramatic difference, but to simplify the story, I will use them as synonyms. Let the fans fuck me up for that, but you'll understand how it works.
💎 Basics of AR: SLAM — Simultaneous Localization and Mapping
💎 Past, Present, and Future of SLAM: Towards the Robust-Perception Age (2016).
The result of SLAM can be either a ‘dense’ or a ‘sparse’ map of the world around you. It is similar to a city map: when you marked only the key objects in the streets — it's sparse, and when you remembered every building up to the number of windows in it — it's a dense map.
Imagine when you sneak into the toilet at night and can't see all the details of the interior, your brain successfully leads you using some ‘contours’ and ‘checkpoints’. That’s a sparse map navigation.
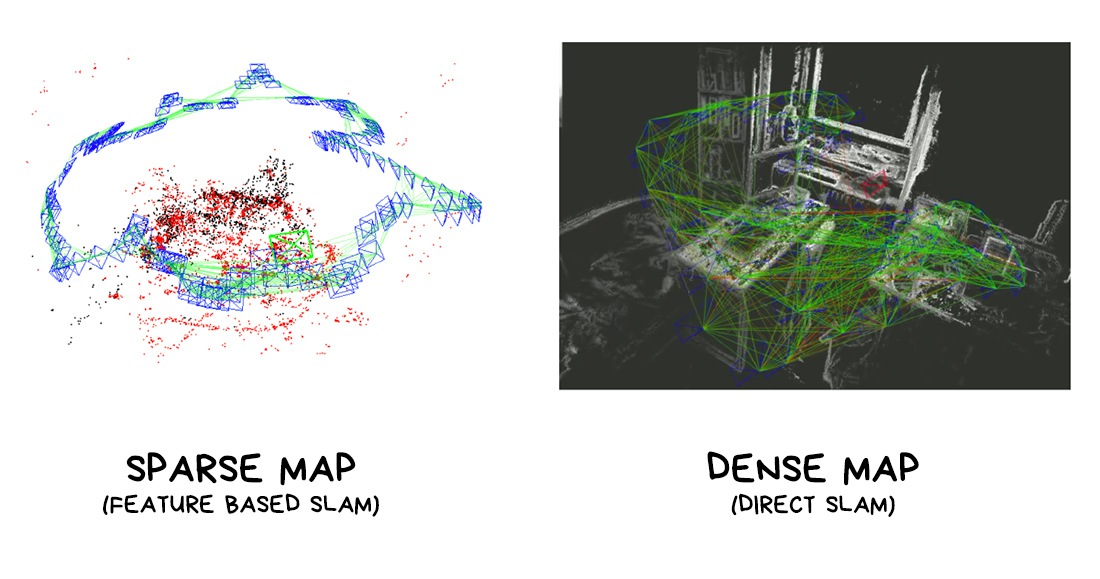
If we abstract from holy wars between fans of different algorithms, then a sparse map is better for position tracking and multiplayer, because it has fewer points, while a dense map is better for rendering, calculating the overlap of objects (occlusion) and lighting, which we will talk about later.
Both maps can be useful, but at different times.
Let's go back to the algorithms.
Any self-respecting SLAM uses any available data sources to collect data about the world around it.
Among them:
🧭 Sensor indications (IMU). ~1000 fps. Accelerometer, gyroscope, compass and everything else.
Sensors are incredibly fast, but their main problem is that they accumulate errors over time. They don't actually ‘see’ the reality, they just ‘feel’ it through acceleration and tilt, so predicting the exact position based on them would be like me telling you that I took 20 steps and then asking to predict how many meters I walked. More steps, more error.
🎥 Video from cameras. ~30-60 fps. Modern phones have multiple cameras, which is pretty useful. Wide lenses are helpful too: they can see more and produce more stable tracking (one of the reasons why the wide lenses are so popular now).
Camera data is supposed to be more accurate than the ‘blind’ sensors, but it also accumulates an error, this one over distance. The good news is that they seem to compensate for each other. The accelerometer degrades with time, camera with distance, so they can eliminate each other's error.
🗜 Depth sensors. ~30 fps. Time-of-Flight cameras will be in every smartphone soon. Kinect and HoloLens already have them. They're mostly using them to reconstruct a 3D map of the world, but they can be pretty useful in SLAM, too.
GPS, BLE, and other positioning systems are hardly used due to their inaccuracy.
Here is an approximate order of steps that we calculate on each frame.
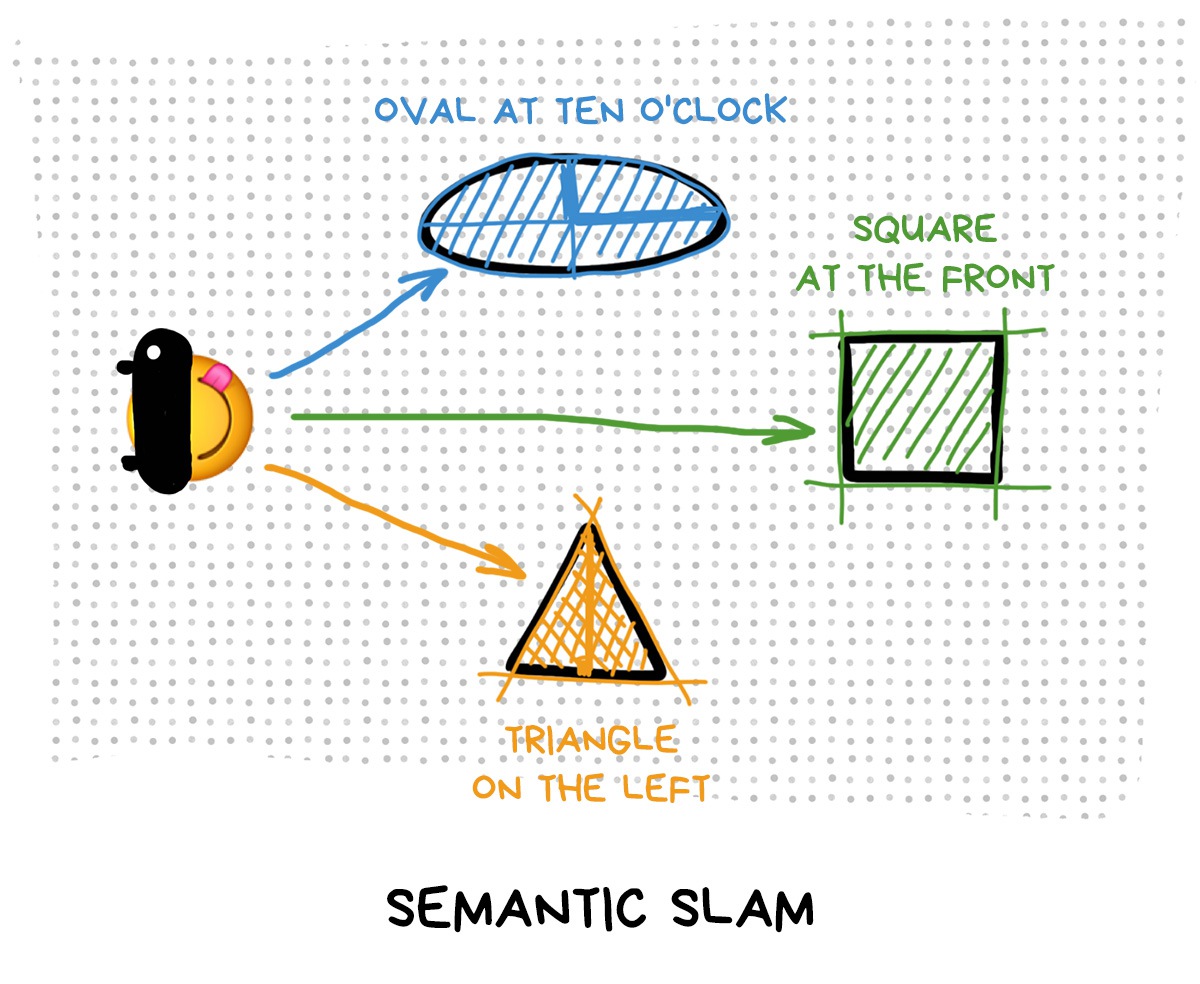
We don't have any picture markers or beacons, so we'll have to find landmarks automatically. There are three levels of abstraction how you can do that:
🛣 Recognize real objects — building, road or nose. Such SLAM is called semantic and is used only where there’s no other way: when a self-driving car needs to track the direction of the road or an instagram influencer wants to put a bunny mask on his face. Both cases are important.
In other cases, doing honest object recognition is too expensive and slow, although many researchers believe that this is the future of AR. Top frameworks today can only recognize popular objects like people, their hands and faces, but don’t use them for SLAM.
Although there are some desperate guys who try.
🌇 Select key environment points. Such SLAM is called Feature Based and is the most popular one today. The algorithm searches for distinctive pieces of objects — the edges of tables, windows, houses, and memorizes them.
Most often in real-world implementations, we just take the corners of all objects with a buffer of 30x30 pixels around. That's usually enough.
Well-known Feature Based algorithms: SIFT, SURF, BRISK, FAST, ORB.
Nowadays, more and more often we use simple ML-models to find the edges. They work even faster.
In this post I will speak mainly about the Feature Based approach, as it is used by all popular frameworks.

🎆 Analyze every pixel of the image. It is called Direct SLAM, and it appeared recently. Basically it's the Feature Based approach, driven to the point of absurdity — we consider every border or even pixel in the image to be a feature.
This way we can immediately get a dense map of the environment, which is very good, but we lose the ability to quickly orient ourselves in space by some key points if we get lost.
Today, direct methods are more often used in machines and robots than in augmented reality devices, but they have their own fans who say that it's the only way to go, because it's only by using all the information about the world that you can create the perfect tracking.
The most famous direct algorithms: DSO and LSD.


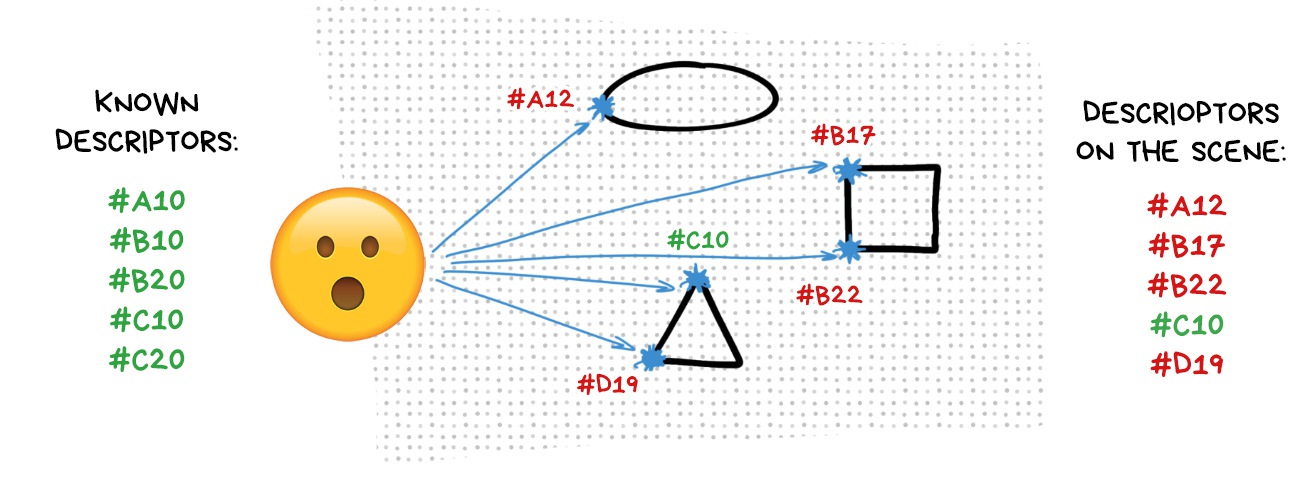
We assign a certain tricky code to each key point we found. It is called a descriptor and there are different methods for calculating them, too, but let's not sink into details right now.
In essence, a descriptor is a hash or a tree which you can quickly match with the same tree from another image (if you have calculated the same descriptors for it).
Just a typical indexing and searching task. Like a phone book.
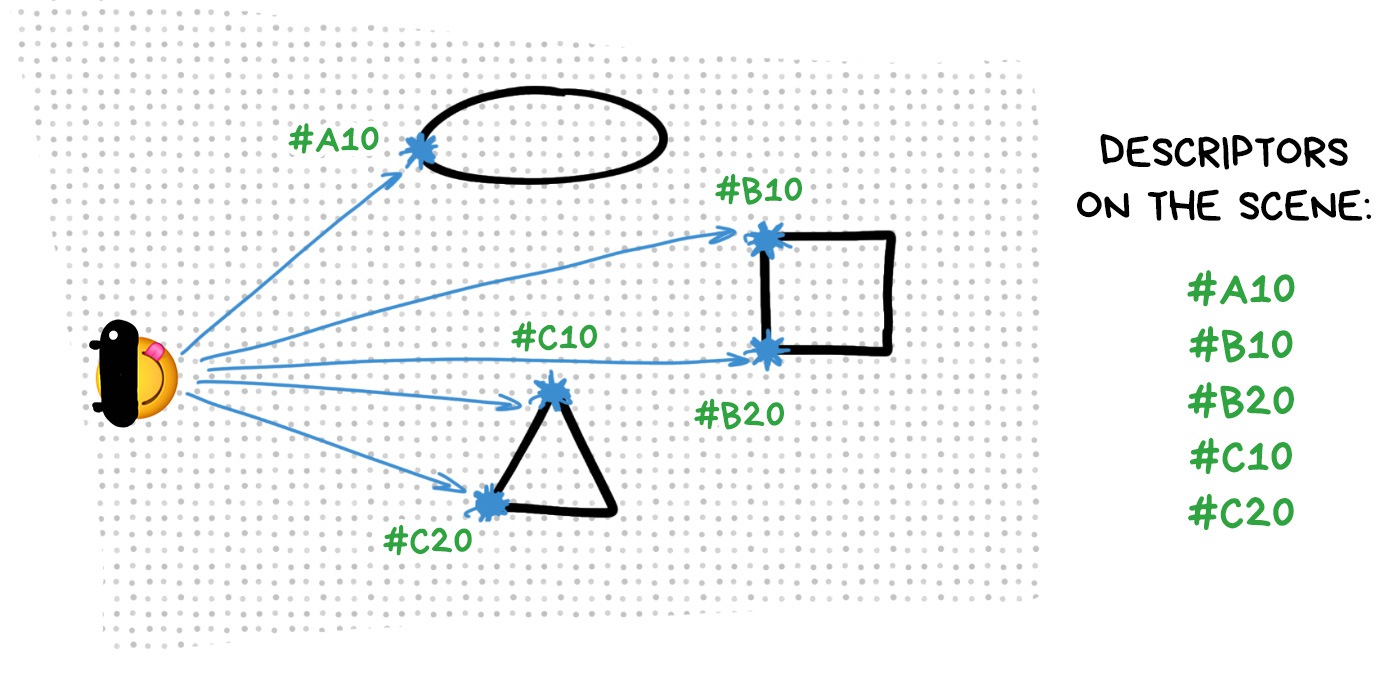
We match the descriptors for each frame: the algorithm determines which key points it already knows from the previous frames, and then does its calculations: one key point has moved 50px to the right, and the other 100px to the left, so I'm now triangulating my new position according to that. Done. Thanks.
Usually, we can find 80% of the descriptors that we already know in a new frame, so our algorithm has no particular problems with localizing.
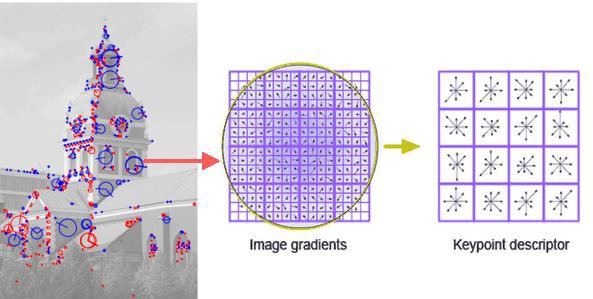
For the curious ones: one of the popular descriptors (SIFT) simply divides the whole area into cells of 4x4 pixels, counts the gradient inside each cell and builds histogram. Such a histogram characterizes the given area accurately enough, plus it’s resistant to rotation. Profit.
💎 OpenCV: Feature Detection and Description
🎥 SD-SLAM ← a point cloud, key frames and a sparse map are clearly visible on this video
Estimating the most likely position with approximate information about it from several sources is a standard local minimization task you get on the last course of your undergrad.
We’ve got data from the sensors such as accelerometer and gyroscope, each with its own accumulated error; add the visual cues from the camera with an approximated distance to them. Let’s go!
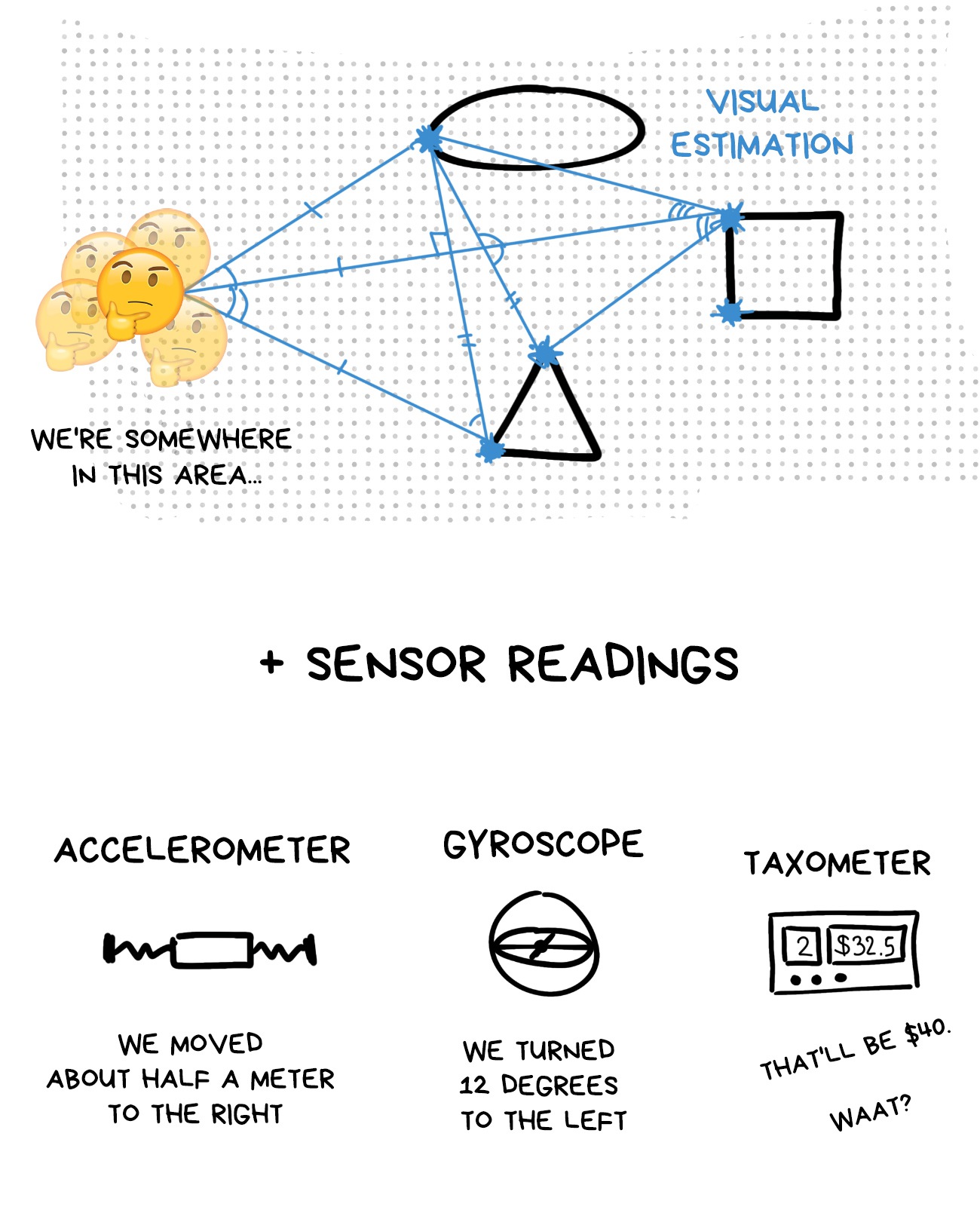
At this point, Automation MScs with Kalman estimators and a maximum a posterior probability estimate crash the party. For a long time, they’ve been using it in autopilots and stabilizing various drone thingies that require getting crap numbers from lots of sensors and returning one that is accurate.
The solution to all these equations is the most probable position of the user’s head in space (Ground Truth). Naturally, the error is accounted for as well.
💎 Why is ARKit better than the alternatives?
💎 How is ARCore better than ARKit?
When you know your position, you can start adjusting the coordinates of those reference points in our 3D environment to improve positioning further in the next frame.
It’s as if we’d be sitting in the middle of the room and estimated there are about three meters to one wall, and five to another. Then we’d measure these distances, I don’t know, with our outstretched hands, and found out one wall was exactly twice further from us than another.
Aha, we’d say, that means it’s probably six meters to this wall, not five.
That’s roughly how SLAM estimates as well, it doesn’t have a ruler. And this charade takes place 30-60 times a second.
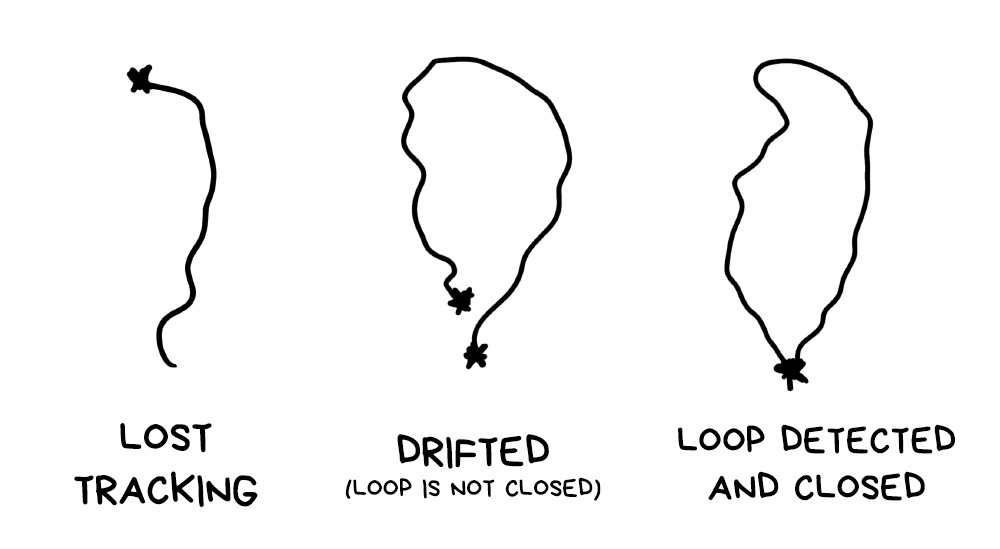
Now for two unnecessary, but desirable steps — they aren’t done for every frame, only for key frames once every several seconds.
Loop Detection. Loop detection is useful, as when we’re circling the room, we’re likely to return to a place we’ve already been in. Then there’s no point to recalculate the map and overlay the maps; it’s better to realize what happened and continue using the old reference points.
This helps improve the stability of the tracking and the precision of the map, as well as saving memory and other resources. In return, once every several frames you have to run this additional check.
Plane Detection. When we see that several points are located on one surface, especially if they are, according to sensors, parallel or perpendicular to the ground, we call it a plane and take it as a basis for our future calculations.
Why? Because it will be a great quick’n’dirty fix for the next step: setting the objects on the stage.
The case described above is quite optimistic. But life is pain, for the most part, and so our SLAM can one day realize it has no idea where it is.
In this case, it runs the ‘I’m lost’ algorithm and starts relocalization. From somewhere in the buffer it loads key frames and all reference points left in the memory. Then, painstakingly, it starts looking for familiar corners on the map to somehow relocalize in relation to them.
I’ll elaborate on that when discussing multiplayer, as a new player joining the map is, in essence, relocalization through other’s reference points.
Ok, we’ve got the environment map, we get where the camera is, sometimes we can even understand where the ground is to put objects on. These are all components of a typical 3D scene, so now we can use any popular engine to render models on it.
Like Unity. Quick and simple. Like instant noodles.
However, on the first try we’re likely to get shit like this:

Our users will laugh at us after this. Unless they’re Pokemon Go fans, of course.
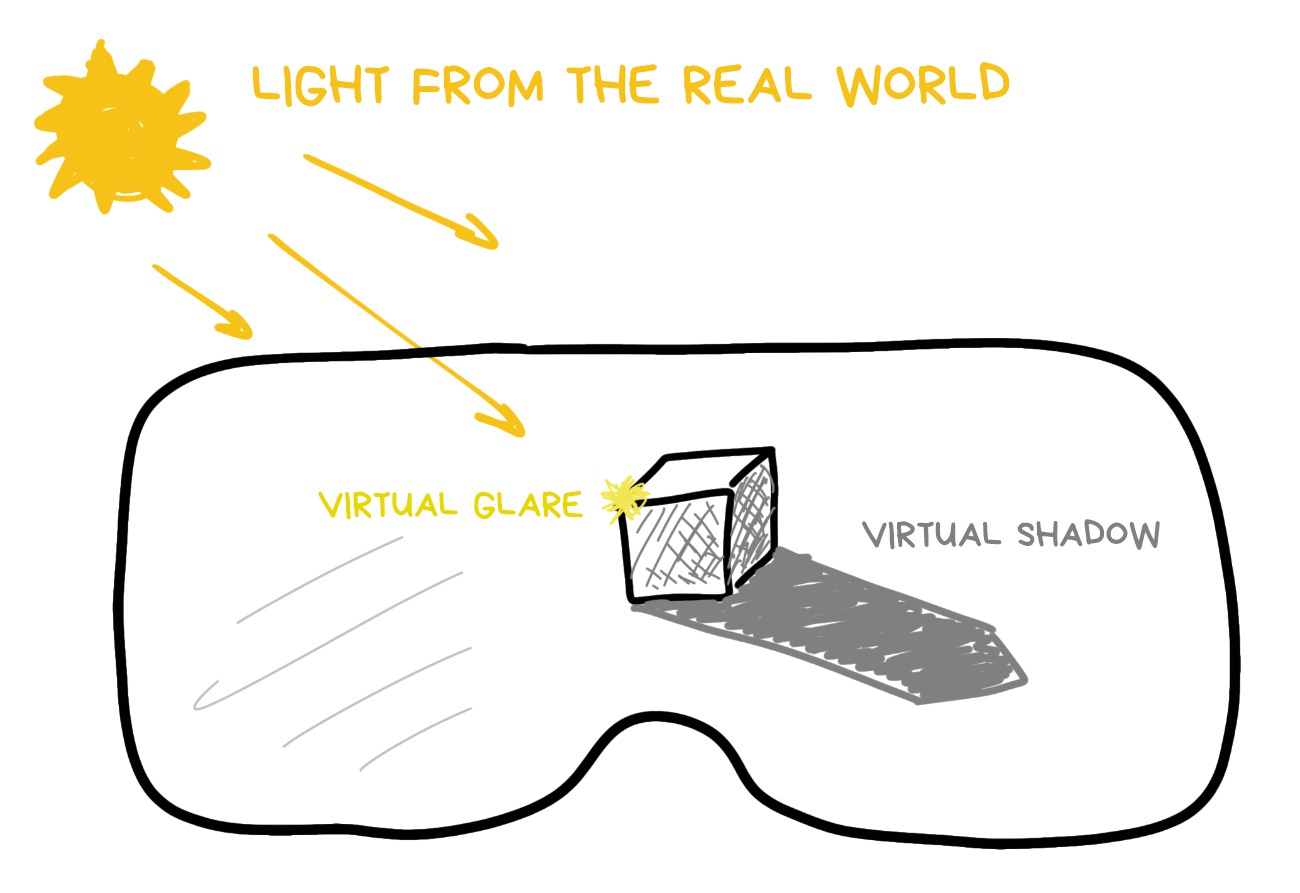
Thus we approach the third most important component of any AR — seamless rendering with light estimation.
Any render works with light and material. Materials are given by the artist making the 3D model, so there are no problems there. Lighting is trickier.
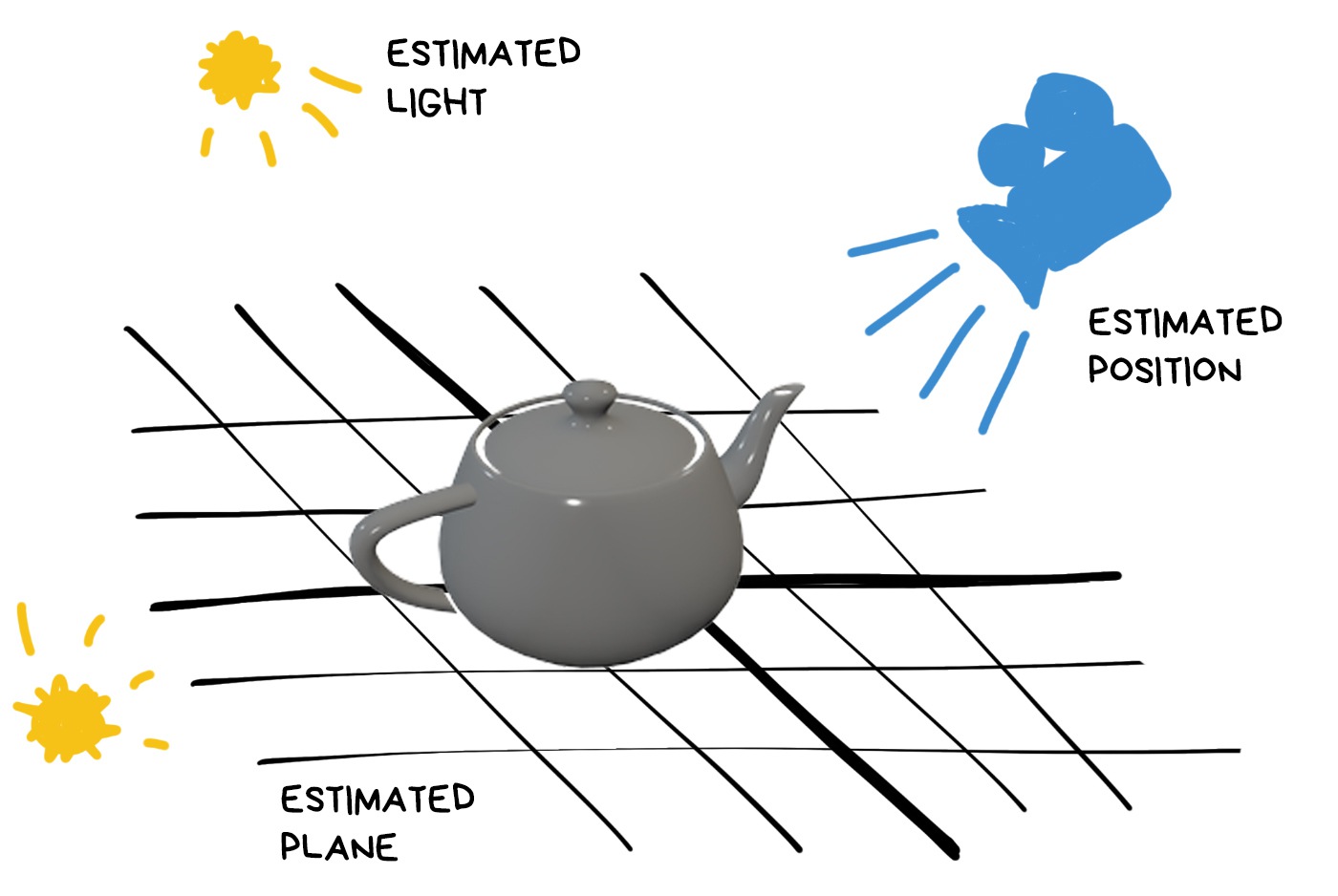
This is not a 3D game where light sources are pre-arranged. Every time, scene lighting depends on where the user opened the app. In addition, we see the surrounding world from a single point, — the camera lens, — while the object can be behind the sofa or across the street. The light conditions there can be drastically different. So, what to do?
This is what Estimation does.
One of the first ideas that occured to our ancient ancestors was to take time and geolocation of the user and, using the simplest formula, calculate where the sun is. Hence you understand where the shadow should fall, and the general contrast of the frame indicates how soft it should be.
By the way, this approach is still used just as a backup. That’s why some AR apps on your phone want geolocation access.

This hack works great out on the street, but indoors it sucks. The light there reflects, disperses, takes on the colours of different objects, and sometimes comes from several sources at once.
All this is much more difficult to calculate.
Desperate academics rushed in to solve this problem, calculating the lamp locations from specular highlights, throwing mirror balls onto the scene, or forecasting the lengths of the shadows through neural networks. While it made for an interesting thesis material, there was no real application.
Still, as a consolation prize, these solutions were dubbed ‘analytical.’ Just so that they could write in each paper that ‘analytical solutions are, as usual, inapplicable.’ Classic.
💎 Realistic Real-Time Outdoor Rendering in Augmented Reality
When in doubt — train a neural network. Everything is clear here: a convolution network that returns a light map at a given point trained on a set of 3D scenes or real spherical photos.
Any school kid with a GeForce 2080 can teach you to do it these days.
I even wrote a post about ML.
💎 Fast Spatially-Varying Indoor Lighting Estimation (2019)
A global light method without additional devices and shadow length divination appeared thanks to the first Kinect with its depth cameras that taught us to quickly calculate approximate 3D environment maps, be it in 640px definition.
In contemporary AR, we’re benefitting from the dense map of the world, provided it has enough points to assemble an environment model.
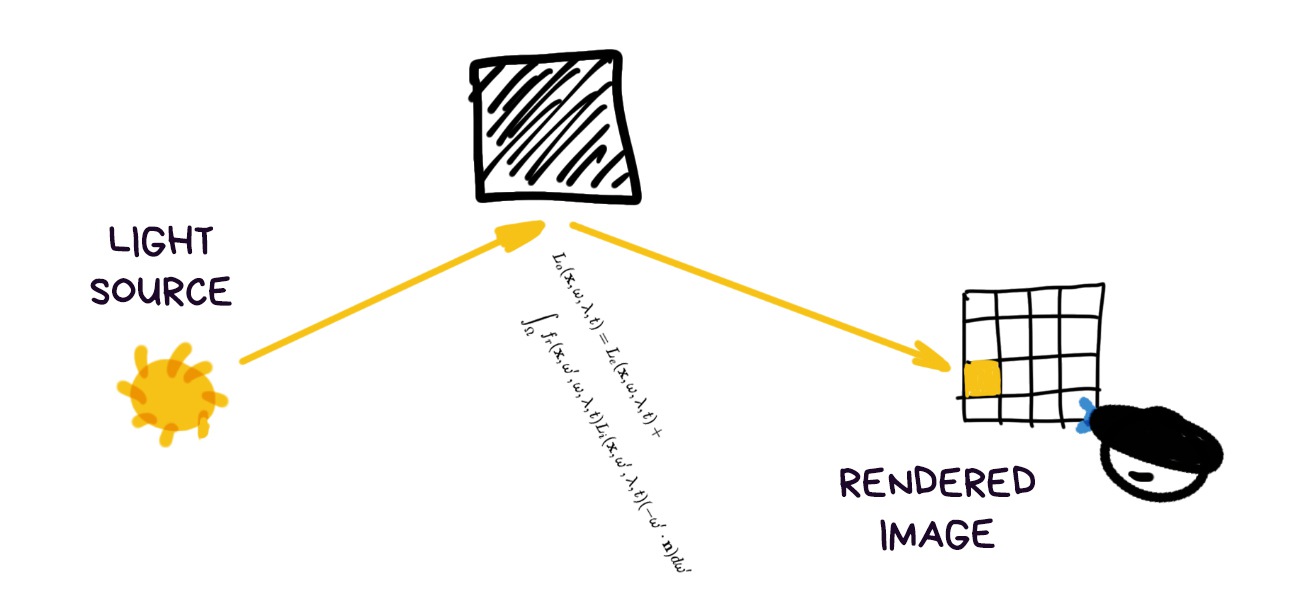
The light communicates with the world through the so-called rendering equation — a long formula that allows calculating how the beam of light is reflected from objects into the camera. For each pixel of the frame.
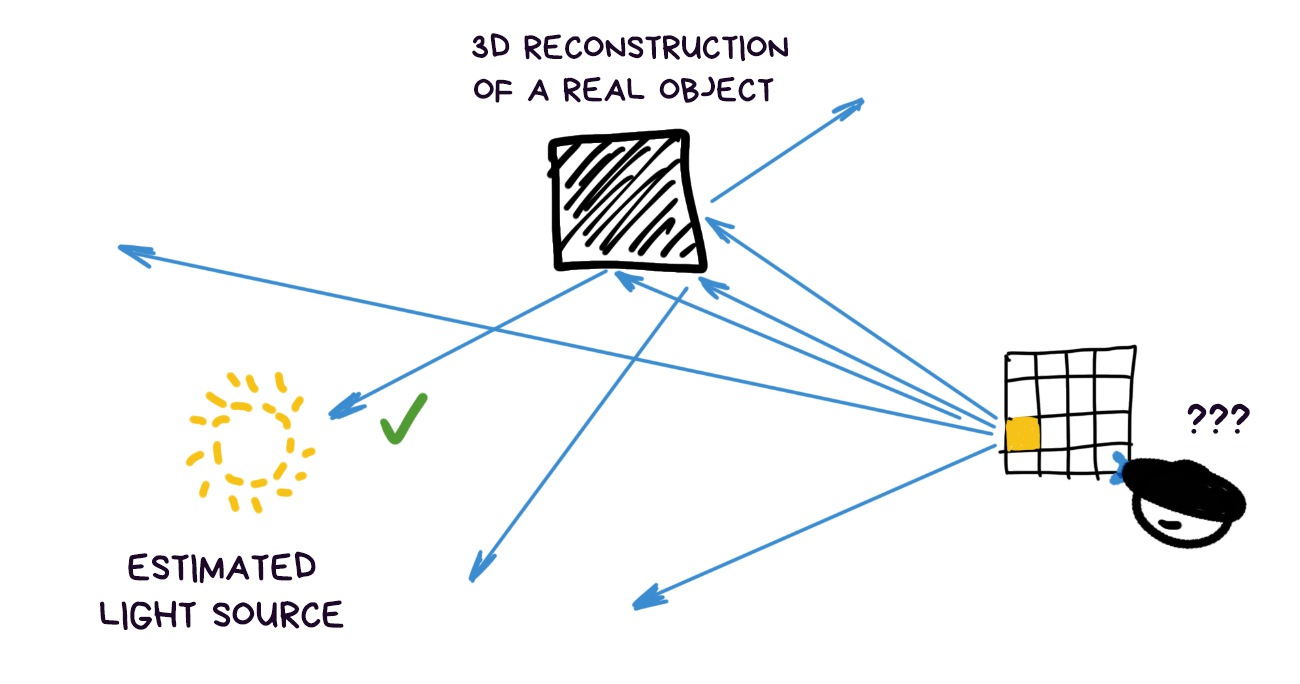
When we have an equation, we can always revert it. For instance, by assuming the light sources as our unknowns. In our case this means calculating light source and quantities based on each pixel’s brightness. Sounds like a plan.
Except, as is common in maths, screwed up backward equations don’t want to be solved analytically. But we’re not little kiddies and can answer with a heavy artillery, such as numerical solution of a system of equations and Monte Carlo methods.
Plainly speaking, we shoot a gun ten times and wherever we hit most often was, most probably, the target. We, engineers, love this shit.
Having collected the most probable solutions in this manner, we can continue approximating where our main light sources are located and how bright they are. More approximations — more accuracy, fewer — faster calculations. Profit.
To avoid remembering each ray of light, and instead pack and present all of them nicely, we use the thing called Spherical Harmonics. It’s less scary than it sounds, it’s just a histogram folded into a pimpled ball and written down as an equation.
I think it will be more clear from the picture. The direction of pimples showы where the light comes from. The more complex the shape — the more precise the light map is, the simpler — the softer.

Mathematically it is, of course, much prettier, including perfect analogies with Fourier transformation and frequency analysis, but you can find out more about that in the links (like I don’t know nobody will bother).
Later, we even learned to take their colour into consideration. Thus, if an object is located next to the red wall, it will be tinted red on one side due to the reflected light.
But that’s hardcore. I don’t know if anyone bothers to get into it at this point. But we can.
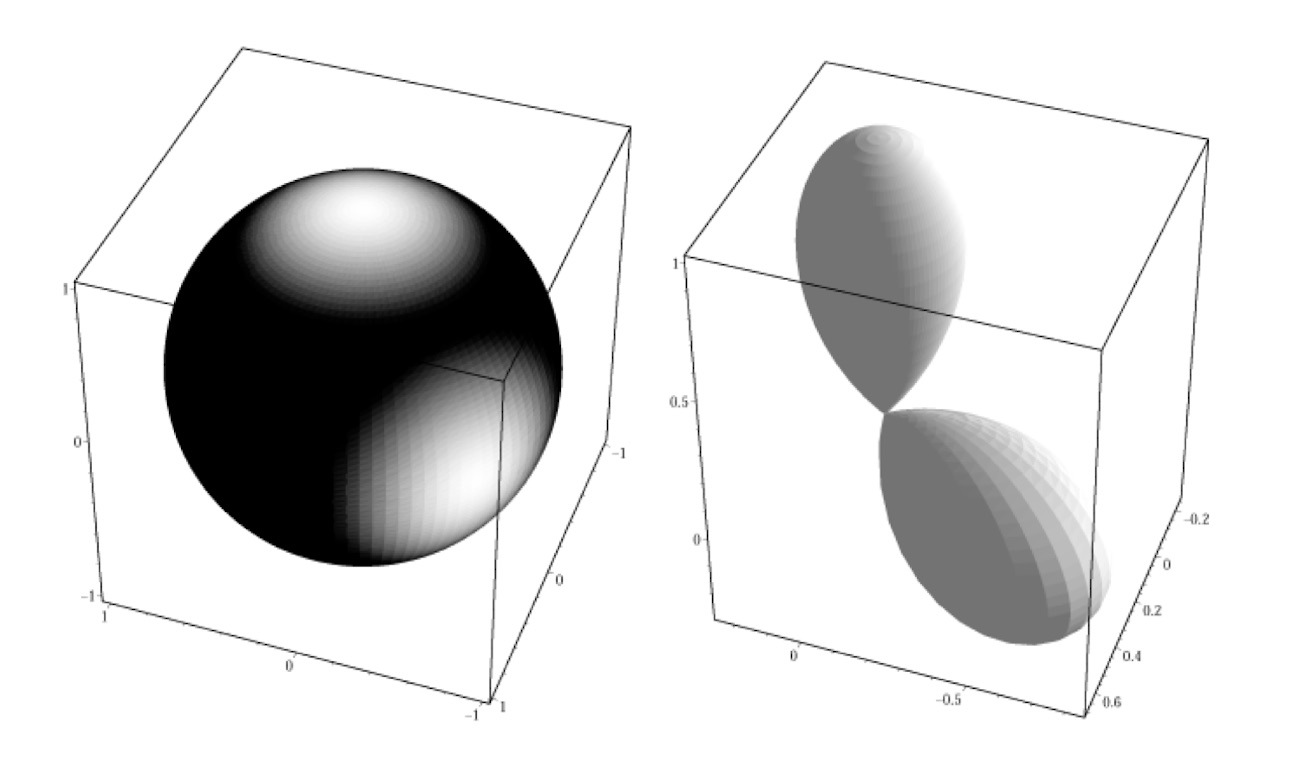
The method is used very actively as it is quick to calculate, optically correct and allows balancing precision and speed. For instance, Google has a very transparent name for it in ARCore — Environmental HDR Ambient Spherical Harmonics. Lol.
Now when you see how a 3D object on AR scene gradually changes brightness and moves from the light into the shadow, you can proudly state that it’s done through spherical harmonics. Cause it sounds cool.
💎 Real-Time Photometric Registration from Arbitrary Geometry (2012)
💎 Spherical Harmonic Lighting: The Gritty Details (2013)
The more we try to make rendering realistic, the more we understand we can’t do without the environment cube mapping.
Cube map works like that: imagine we took a picture of the surrounding world in six directions, and then assembled it into a cube. Such maps have been long used to model realistic reflections, however, in moden AR, they also help with light forecasting.
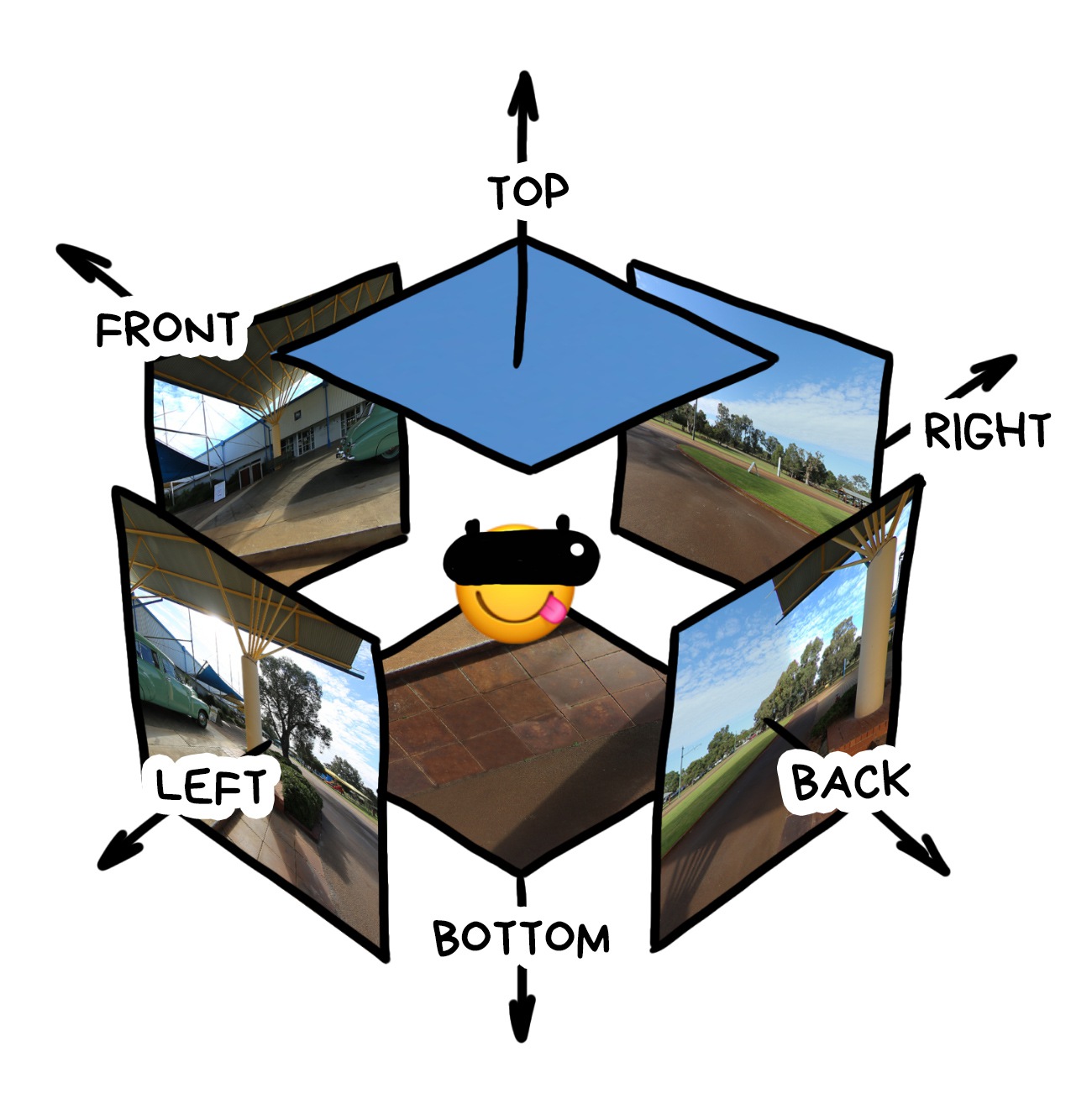
More info for the nerds: cube maps are tightly interconnected with Light Fields from my previous post. In essence, one cube map is a two-dimensional light field, and several cube maps are a 4D one. In theory, the latter lets us calculate the image from any point in space, because it actually knows about all the light rays in the room. But I haven’t heard about anybody going this far yet.
So, one of the AR gadget’s most important background tasks is to record and constantly adjust environmental cube mapping. Any life hacks will do: robots enjoy the fish-eye lens, helms get rear view cameras, whereas phones sneakily use the front cameras to look behind your back.
When even this data is not enough, we bring back the neural networks. It’s the same thing we did with light mapping, only now we use them to fill in the missing elements of the world.
That’s what iPhone’s doing with ARKit. It just draws the remainder of your room based on whatever it can see through the camera lens. Nobody will notice the difference in a blurry reflection, anyway.

The next steps are clear: if an object is even slightly glossy, we put it in the center of the cube map and calculate how it reflects in the model.
We’ve fallen in love with cube mapping so much we start replacing all the other puny light calculation algorithms with it. Why have difficult equations if we can blur and pixelate the world map, and then look which part of it is sunny and which one is dark?
These calculations are so easy it looks like all popular frameworks will use cube maps for light estimation in near future.
💎 Dynamic Environment Mapping for AR Applications on Mobile Devices (2018)
Rendering is a process of generating an image from a 3D model while taking into account all conditions of the scene. In augmented reality, it’s not that different from any video game, so every school kid would have a good idea about the engines’ capabilities.
The only difference is now we have transparent parts of the scene that don’t make it onto the final image. Take, for instance, the world map. It reflects light onto objects, which in turn can cast shadows on it, but it’s invisible in the final image. Instead, we expect to see real world objects, and that’s where the magic happens.
Let’s refresh at least the basic components of any render and see how they are calculated based on everything we’ve learned so far.

First, we need to understand that the modern AR world renders at the level of video games from the beginning of the noughties. There’s not enough computing power, and often there’s no need for more. People bother with rendering objects onto the scene realistically only to get static photos. There, you can really go to town on a hundred layers of shading.
📝 Using ARCore to light models in a scene
General frame lighting. In popular frameworks it’s represented by two numbers: light intensity (dark ↔︎ light) and light temperature in Kelvin (blue ↔︎ yellow).
Both are calculated with a simple average of pixels from the last seen frames, you don’t even have to think that hard. Both numbers are global for all objects and, in essence, act as a baseline for the following rendering.

As we’ve established earlier, light sources are calculated through reverse rendering. We can calculate light for each object on the scene, but that’s hard; or we can do it globally just once, and then simply render the same light on all objects. This is called Global Light Estimation, and it’s the only thing many companies do these days.
Except Microsoft, who can calculate light for each vertex of an object.
In any case, we get a sort of invisible flashlight that shines upon an object from the right angle. Then it’s up to rendering.

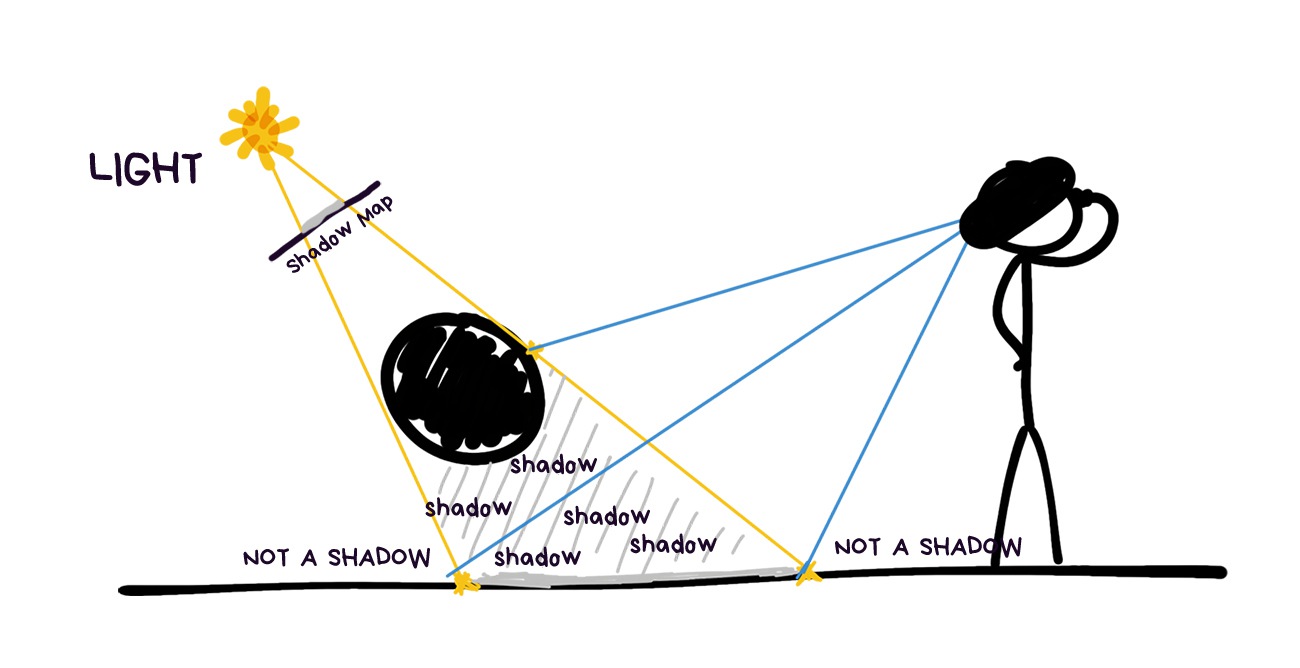
We get shadow as a bonus to go with the light sources, calculated in the previous step. Next, we take the simplest and quickest methods for their calculation, because there’s no point getting bogged down with the perfect shadows when your entire world calculations contain errors.
The same old Shadow Mapping will do the job just fine. We sort of assume the position of each light source: the parts of the objects we can see from their point of view will be lit, whatever we can’t see is in the shadow. It’s that simple. Then, we put it on one single global map, and there you have it.
Even in the modern AR engines objects usually cast shadows only on the plane underneath them, but I think developers coming around to make them more realistic is a question of time.
For now, that’s enough.
Specular highlights and shading are two sides of the same coin. Specular highlight occurs wherever the light ray reflects from the object directly into the camera. Shading, on the contrary, is reflected anywhere but into the camera.
Both parameters are dependent on the object properties and change with the observer’s position.
Reflections of the cube map of the world are layered over every object. The glossy ones reflect it like a mirror, whereas the matted ones simply get slightly tinted with the colors characteristic to the surrounding.
In ARKit, this feature is called Environment Texturing, other engines have it too, they just call it differently.
The difference between pure rendering and overlaying even the lamest cube maps calculated by neural network immediately catches the eye.

This is a type of reflections where light, reflecting from one object to another, slightly tints the second one with the first one’s color.

That’s also done with spherical harmonics, provided their algorithm can do colors.
How? Well, we shine random light rays from the centre of the object in all directions and see what will be the first world object they come across, what color is it and how far away it’s situated.
What’s the most annoying thing in AR apps? This crap:
Absolutely disgusting.
However, it doesn’t change the fact that IKEA Place is one of the few actually useful AR apps.
Naturally, we understand that virtual world objects are always drawn atop the real world, but wouldn’t it be cool if they would also understand that anything can come between them and the camera.
This is called occlusion.
There’s only one choice here: you have to artificially cut the parts of the objects that are covered by the real ones. This will create the appearance of a virtual cat ‘hiding’ behind the sofa, not rendering atop of it.
Only a couple of years ago nobody could solve occlusion. Now, we’re getting the first affordable real-time solutions in ARCore, as well as understanding where to go next and what sensors to buy.
It will be completely fine in a couple of years.

Depth map or z-buffer in computer graphics. It can be calculated based on several cameras’ viewpoints, or filmed by the depth camera if there is one.
You can do it with one camera, it’s called Structure from Motion, but it’ll have a terrible parallax error, so take two cameras for good measure.
A depth map from a modern smartphone with Time-of-Flight or a stereo camera will look something like this:

When we use it to calculate all distances, carefully layer it on our 3D scene and figure out which objects ended up being blocked, this will be the result:

Welp. No cyberpunk for us at this rate.
We’ve got lots of problems. First, mobile depth cameras have very poor resolution; second, they only work well on the distance from 50 cm to 4 meters; third, they fail miserably outdoors because the infrared light from the sun blocks out their own. It’s like switching on a flashlight on a sunny day.
Calculating depth from several cameras is only marginally better. The resolution is higher, but there’s more ambient noise than in a bar on Friday.
You can go further and tap into alternative methods. Face ID, for instance, used Dot Projector in connection with a usual infrared camera to do the same thing. As they needed both speed and precision, they were justified in reinventing this tricky wheel.
We still need depth maps as a basis for more complex methods. To sum up, we can’t do without them, and they became the cameras’ key area of development.

We’ve already used 3D environment maps to forecast the real world light. It’s time to elaborate.
We need an extremely precise model of the environment for occlusion. If it’s enough to understand where’s the wall and where’s the table to model light, here we need a more meticulous reconstruction, unless we want to get the kettle from the image above.
Good news, everyone: we don’t need to do it for every frame, so we can save some effort here. It’s enough to upload key frames from SLAM into a separate processing thread a couple of times a second, and there we can calculate the 3D map of the world without disturbing anyone.
Historically, the depth maps we got in the previous step were used exactly for this purpose. The resolution isn’t that important, but we need frames from different viewpoints.
The more — the merrier.
We know the camera position in each frame thanks to SLAM, and it’s easy to get the depth of each pixel from Depth Maps. Hence, in theory, we’ve got all the data in three dimensions required to build a 3D map of the world.
In practice, the method used for it is rather funny and reminds gift wrapping. We take an easy object with a bunch of apexes (let’s take a sheet 5000x5000 points) and ‘fold’ its apexes to the places indicated on depth maps.
Just like a cube shrivelling into a rabbit in the gif above.
For nerds: in essence, any operation of building a 3D map from depth maps boils down to converging apexes to the nearest local minimum, which computational chemistry calls «energy minimization». Yay, that one time your chemistry class finally has real life relevance!
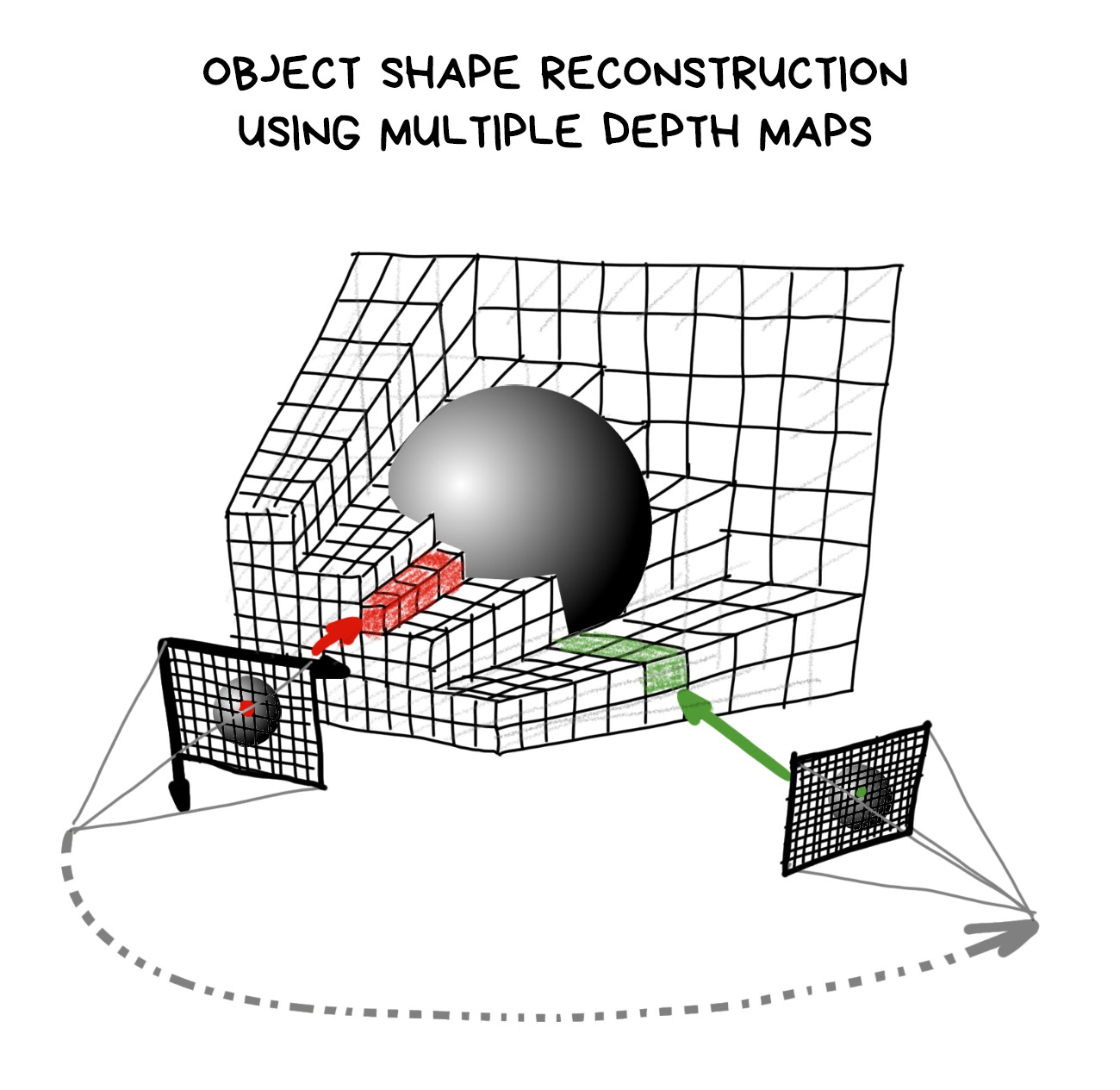
‘Wait!’ the only three people who are still reading this post may shout. ‘But if prior to this we need to do SLAM to define the point where the depth was measured anyway, why don’t we just take an algorithm that creates a dense world map and uses it for localization? Then we don’t even need a depth camera!’
I see some great wisdom in your words, young Jedi.
The state-of-the-art is as such: we get SLAM to give us as many points as possible, cover them with triangles and smooth the resulting model with various filters. And done. We have a 3D-model!
SLAM itself can use these additional points for tracking, so this brings us closer to Direct SLAM (we just need to throw away the descriptors and that’s it). This approach kills two birds with one stone, that’s why it got so many fans.
💎 DTAM: Dense Tracking and Mapping in Real-Time (2011)

All these methods put together are called photogrammetry
And it’s not some overhyped word from sci fi, it’s a mundane reality. For about a decade now, photogrammetry has been used to cobble together 3D models for video games. Modellers draw only the most important parts: characters, vehicles, animals, whereas stuff like bananas and street litter is just scanned in 3D alongside their textures (or bought from stock archives).
Google Maps uses it for 3D maps of the cities, while drone owners fly around various cathedrals, creating their virtual backups. Theoretically, we can turn any video with static objects into a 3D scene.
Finally, every school kid’s dream came true: you can now create the model of your neighborhood and drive around it in GTA.
Only these school kids don’t care anymore, they’re all forty now.
Coming back to the occlusion problem: with the precise map of the surrounding its solution lies purely in the realm of geometry. When the render sees that one part of the object got covered by a piece of map it renews the red code and starts computing where to cut it.
Of course, you have to struggle with the noise and accuracy errors all the way, but we, the Real Men (and Women), can just cry out loud after that, because now it's socially acceptable.
The main problem of the whole thing is this: the result is a very noisy and bumpy model, and it becomes total garbage when a dynamic object appears on stage. Like a cat passing by grows into the wooden floor and becomes a piece of furniture.
And you need to start it over again.
The real party begins with complex moving objects, especially with people: there are too many of them and they always get into the frame.
Even your own hand is a source of problems. Say, you want to wave it in front of the camera or grab a 3D object. Your fingers need to sort of lie on top of it, while the remainder of the hand goes behind it. Terrifying.

You can’t do with depth maps alone here, and a 3D reconstruction will just go mental.
The only option is to make an honest object recognition. For people you have PoseNet, for objects — ShapeNet or Detectron, but you can’t just use either off the shelf: they can’t do 30 fps.
Hence everyone’s writing their own fixes, and even at some cool companies’ presentations you can see it doesn’t work all that well.
Big boys assemble their pipelines from all the abovementioned. First, they calculate a 3D map, then observe moving objects through a depth camera, then recognize people and their limbs through different ML identifiers.
Human figures are then adjusted through the depth map, but in a more targeted way.
When these methods are not enough (more often than not), you see hacks such as border detectors or Guided Filter from OpenCV. They calculate object shapes based on the pictures like a Photoshop magic wand, and then we can somehow average them out with the camera data and make the borders less ragged.

The main problem of these hacks is that they are often ungodly slow. Sometimes as bad as 3-4 fps. Nobody's gonna like such a flabby pipeline.
So, let’s wait until high resolution cameras will be everywhere. They will end all this suffering (and bring in new ones).
💎 Fast Depth Densification for Occlusion-aware Augmented Reality (2019)
🎥 Video teaser for the paper above

At this stage we know how to track position, we’ve got the most realistic render possible and overlapped objects perfectly. It’s all great, but we’re still alone. Just like in real life.
The real benefit from augmented reality comes from interacting with other people. We need multiplayer.
Technically, the main task of AR multiplayer is to create a single world map and understand where each of the players is on it. After that, their SLAMs can manage with monitoring the changes on their own. We know that because online games have done it before.
There’s only one problem: how to assemble everyone at the same place to start with?
Let’s start at the beginning.
💎 Multiplayer AR — why it’s quite hard

In the beginning, each player knows only their own world map. These are points that their SLAM saw and identified. It could have measured distance in fathoms and angles in Kim Kardashian’s curves for all we care, as long as the measurements allow it to navigate.
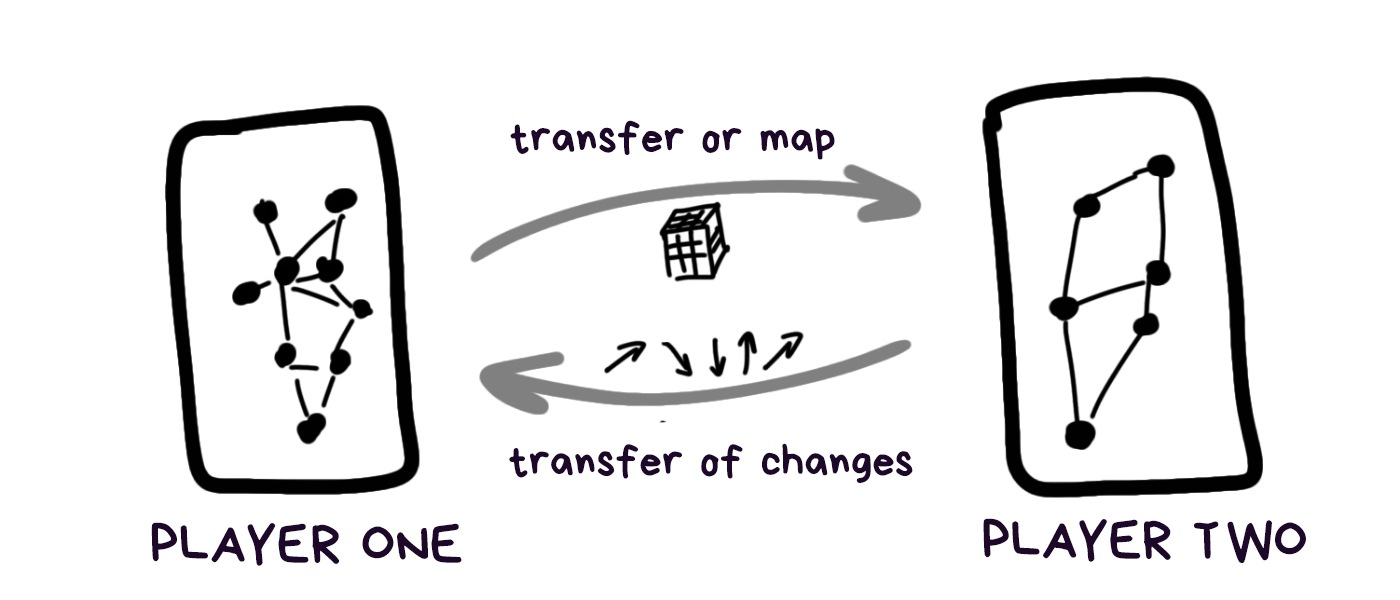
When there are multiple players, you have to recalibrate and negotiate. You need to collect all reference points of their sparse maps in a unified format and pass them to another device or into the cloud.
It doesn’t sound like rocket science, — just pack and send a file, — but the devil is in detail. For starters, it doesn’t hurt to make sure that the players are actually close to each other; alternatively, if it’s a saved session, to re-attach it to the world coordinates, but GPS on different devices can easily have a 200-meter error.
The additional complication is that we don’t have tried and tested or standardized ways to serialize and send such maps. Each framework invents its own wheel, such as ARWorldMap in ARKit, and nobody can reconcile the different platforms at this point.

Even if we manage to standardize all formats and coordinate grids, a 3D map created on one device can be physically bigger or smaller on another, depending on sensor calibration, camera angle and accelerometer manufacturer.
One phone can assess the travelled distance as 50 cm, and another can assess the same distance as 52 cm, and this error fluctuates depending on the lens’ curve. Each device on its own doesn’t give a damn about such an error, because it’s constant, but when both of them end up on the same coordinate grid, well, Press F to Pay Respects.

But this is just the beginning.
🎥 WWDC19: Introducing ARKit 3 ← it’s a good showcase of multiplayer and human recognition
When players exchanged the maps, a lottery starts: will a newly connected player be able to find herself on a common map? To do this, she will first have to calculate her own map, find reference points on it, identify her location, and then try to match all this stuff with reference points on the common map, thus ‘layering’ one world atop another.
In essence, that’s exactly what a single player does if her device lost its precise location when the objects have already been placed and cannot be lost. This is called a relocalization.
Imagine that you are locked in a dark room with your neighbor, each of you is given a pack of photos of surrounding streets and told to use them to calculate where you are to within a single centimeter.
On top of that, you’d better be done within five seconds, or the user will bail and give you a bad App Store review.
Developers’ ‘favourite’ situation is when the players are facing each other. So, in essence, they see nothing of what their opponent’s camera sees. Not a single reference point.
And now you know why some AR games make you stand next to each other to start..
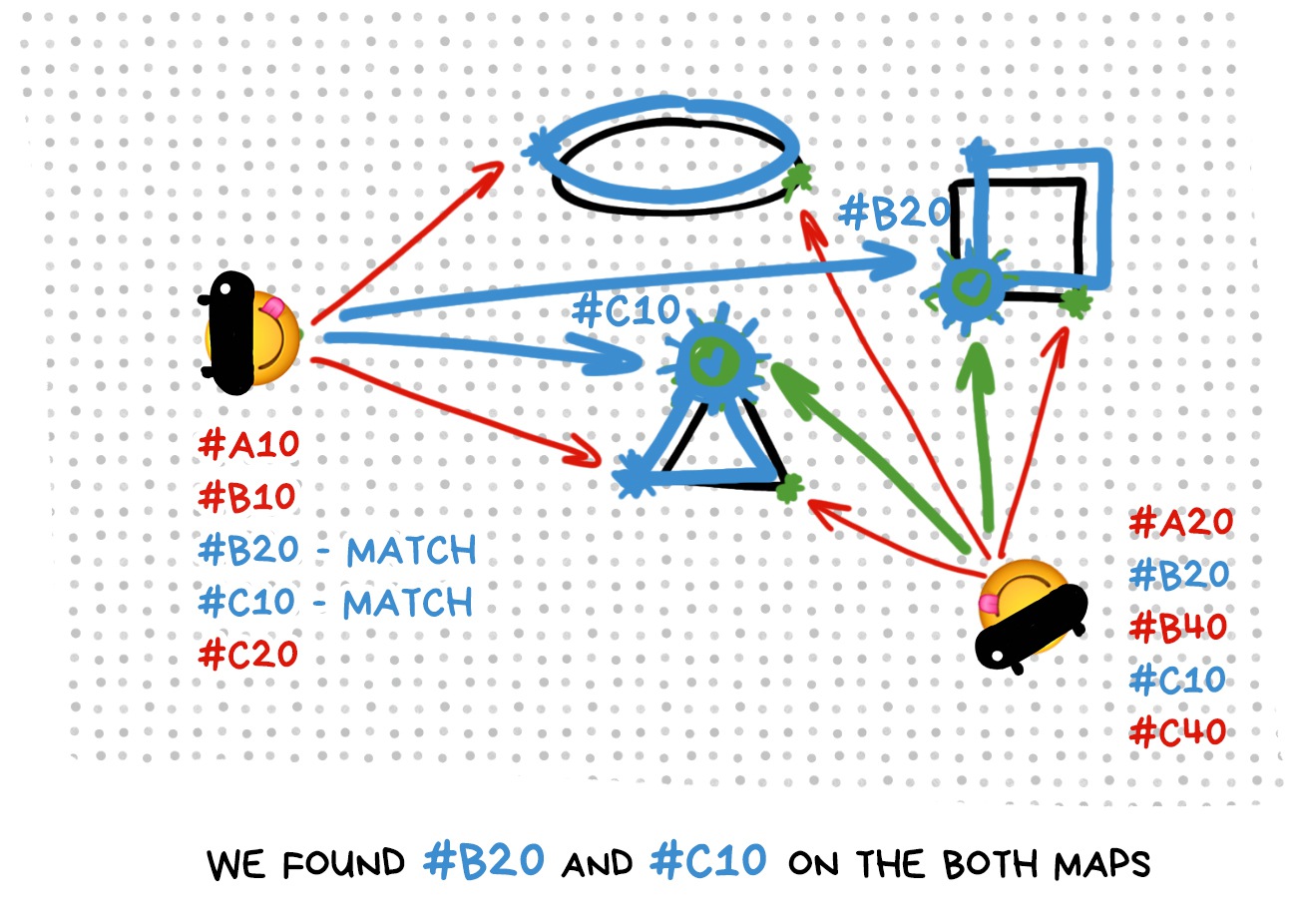
Copying SLAM map with the subsequent relocalization is only one of the available methods, and not the most popular at that. Most often, the costly and time-consuming relocalization is avoided, that’s why the following options are popular:
Do nothing. Just locate yourself again or place objects randomly. Design the app in a way that makes losing the world and recreating it from scratch unnoticeable. A lost robot, for example, may just rescan everything around and continue doing his job, instead of frantically trying to find familiar corners.
Fine, use the markers. Yeah, that’s old school, but if you’re making, for instance, an AR board game, your players will look at the field anyway, so it can be a convenient coordinate grid for everyone. You don’t even need to transfer and synchronize everything.
Use GPS or compass. Remember Pokemon Go. The same pokemon appeared to different players with an error of 300 meters. Developers just didn’t bother with any synchronization and decided that a UX like that is enough. That can also work.
Thirty times a second, each device calculates its new position and has to tell others about it somehow. Moreover, if the players can shoot at each other or interact in some other way, all of this needs to be synchronized, too.
There are two options: send everything online like in a MMORPG, or send directly between devices, like music over bluetooth. In reality both methods are used. Google prefers its clouds for ARCore, whereas Apple uses the good old Multipeer Connectivity, like in AirDrop, for ARKit.
Both options, as usual, have their drawbacks.
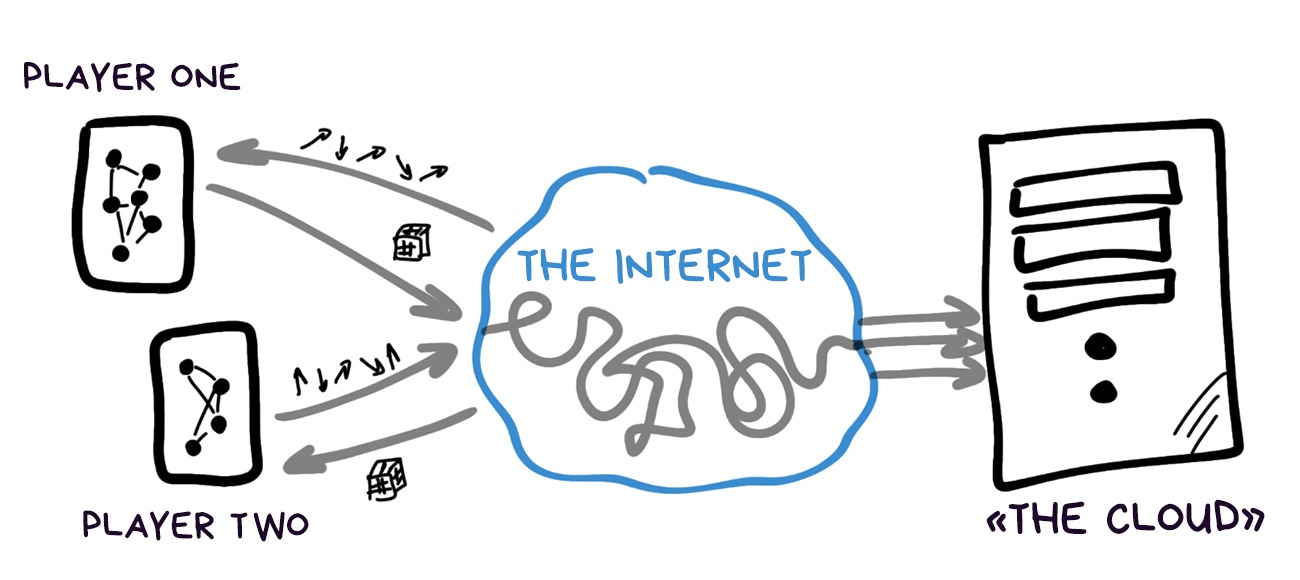
✅ Higher transmission speed
✅ Can store huge world maps
✅ Can do complex calculations
✅ Theoretically, allow unlimited players
⛔️ Require constant internet connection
⛔️ Privacy issues
✅ Doesn’t require internet connection
✅ Lower lag
✅ Cheaper
⛔️ Unstable if players move away from each other
⛔️ It’s more complicated to solve collisions, such as who shot whom first (usually, the first player is simply made the host)
⛔️ Maps have to be small for more convenient storage and transfer
⛔️ Up to 6 devices only (right now)
After that, it’s standard for any online game: open the socket and put bites in it, communicating any changes.
💎 ShareAR: Communication-Efficient Multi-User Mobile Augmented Reality (2019)
Finally, let’s get into the frameworks flame war, so that you’ve got something to discuss in a bar after one too many drinks.
To be honest, it’s Wild West out there so far. There’s no open source, vendor-lock is everywhere, meta frameworks are just starting to appear, even commercial engines from private companies can satisfy only basic needs.
You are most likely to be completely tied up with a specific platform that always has its own language and framework. The way market works is each device is suited to a very narrow range of tasks, so you first look for the right hardware and then write for it in whatever is out there.
However, VR already made it to cross-platform, so, AR won’t be far behind. Hopefully.
Let’s compare the balance of power as of 2020. It all changes rapidly, so you can write in the comments when the new updates are out.
Note: I'm not and have never been affiliated with any of these companies.

Apple are experts in wrapping it up and presenting everything nicely. They’ve started their journey with buying a couple dozen AR companies, and then focusing them to the most visible features for the users: stable tracking, pretty reflections and multiplayer.
These thing are just easier to sell while their developers work on everything else.
Across three years, ARKit has had three major versions:
1.0. Basic functionality like tracking, basic Light Estimation and Unity plugins.
2.0. Added cube maps of environment, loading and saving models, face tracking, object recognition and several features for renders, such as reflections.
3.0. Normal multiplayer, People Occlusion, RealityKit. Sneakily discontinued old iPhone support because a manager told them to boost sales.
The main feature people praise ARKit for is the most stable tracking on the market. Jumping objects occur far rarer than on other engines. Even monochromatic surfaces such as tables or walls are identified correctly, which used to be considered an incredibly difficult task.
ARKit uses simplified SLAM algorithm called Visual-Intertial Odometry, that almost completely removed the M (mapping), but perfected the L (localization) in SLAM, thus causing epic flame wars over definitions, but I won’t go there right now.
Apple abandoned the ‘real’ dense mapping to do as many operations as possible on the device, and the memory isn’t infinite. Therefore, as you might have guessed, light and occlusion aren’t great. They’ll be solving this issue with some fixes.
Still, tracking ended up great. It’s all about precise calibration of sensors and cameras that only Apple can afford.
Hardware sensor calibration is very important for stable AR, so much that circuitry engineers use connectors to close circuit between clocks on different sensors, so that data from them would arrive at the same time. That’s something you can attempt only if you’re making your own hardware.
The same is as usual. Briefly, ARKit has:
✅ Very stable tracking. Thanks to calibration.
✅ Object recognition and People Occlusion.
✅ Peer-to-peer multiplayer. Works without internet connection.
💩 Doesn’t even attempt lighting. It only forecasts shadow and brightness, and doesn’t do it all that well.
💩 Can’t do object occlusion, only people.
💩 Only one platform. Give 30% of your revenue to AppStore forever!

The base code goes all the way back to Project Tango that Google was developing until 2014, and was trying to sell through Lenovo tablets.
In 2017, ARKit launches, Tango code gets forked, half of the ‘useless’ features (like depth sensor support) are thrown out, and it’s released under the name of ARCore in March 2018.
Certainly, it progressed massively since then, nicking many pieces of Daydream VR from the very same Google. They confidently state that all similarities are purely coincidental. But we know the truth.
Unlike ARKit that tries to do everything on the device, Google doesn’t bother and sends everything through their clouds. This makes ARCore better at the ‘real’ dense mapping, object recognition, relocalization and even multiplayer, since it does all of it on servers with massive GeForces.
Google even learned to map and save complete huge scenes on the servers: your entire room, trade center or even the whole airport, doing SLAM navigation instead of jumpy and imprecise GPS. This is top notch.
Besides, ARCore is considered to have a better render with Lighting API that can do every state-of-art algorithm described in this article. Theoretically, it should ensure that ARCore objects should fit with reality much better than others.
As is usual with Android, segmentation is a problem. When you have a whole zoo of Xiaomis and Samsungs to manage, nobody cares how great your algorithms are.
To sum up ARCore:
✅ Has everything ARKit has
✅ Is much better with object lighting
✅ Relocalizes much quicker when lost. Because it stores full maps on the cloud, and doesn’t try to save memory like ARKit.
✅ Attempts an honest object occlusion
💩 Wild segmentation. You have to have the ‘right’ smartphone for ARCore to work really well.

There’s something weird going on in Microsoft again.Their MRTK is a cut above the competition in terms of features, AND can be integrated with everything (ARKit + ARCore + Unity), AND is open source.
At the same time, nobody talks about it, there are no ads, hipster-analytics from Buzzfeed don’t mention it in every article about "Ten frameworks you should try this summer".
It’s just not trendy.
Mixed Reality ToolKit can do everything ARKit and ARCore can, as well as:
✅ Works on a bunch of platforms.
✅ Can track hands and pupils.
✅ Provides a UI library to create virtual forms and sliders that you can move with your bare hands.
✅ 3D mapping of surroundings and off-the-shelf occlusion.
✅ Can be integrated with all popular engines from Unity to Unreal Engine.
✅ You can write traditional 2D apps using standard Windows frameworks.
But that’s Microsoft for you, they have a unique skill to fuck everything up even being in the best position.

All this can work on HoloLens, which beats all your fancy arkits and arcores cold in tracking thanks to its hardware. Microsoft jampacked HoloLens full of ASICs — special chips that perform the algorithms described in this article on a hardware level (!), which is what provides the boost.
And all this technological cornucopia is made exclusively for business clients and enterprises, while we get whatever got thrown into open source. And not even advertised. A single contract with Boeing brings in more than games sold to geeks. Priorities.
Although you too can buy Developer Kit for three thousand bucks, but why? Better watch the demo video below.
💎 Localization Limitations of ARCore, ARKit, and Hololens in Dynamic Large-Scale Industry Environments

There are dozens of cross-platform frameworks sold on commercial license on the market, I can spend hours listing them all. Here are the three most popular in the descending order of the number of apps made with them in App Store and Google Play.

Vuforia is miles ahead so far. Even ARKit and ARCore come second in their own stores. However, its developers start realizing that native solutions will bite a huge chunk out of them, so the new versions actively introduce various platform support un an attempt to become a meta-framework.
We’ll see. It seems to be the right path to take.
In terms of feature set they can be argued to be on par with the big boys described above. Each has its own SLAM, Light Estimation of sorts, OpenGL renders and Unity plugins.
But you have to be careful here. Skateboard has four wheels, but it doesn’t drive like a car. Give it a spin to understand.
Thus, so far this is the path of the brave. Or stingy.
Away with evil corporations, we can do everything ourselves!!!11
Aaand… no, we can’t. Even the most popular solutions can at most identify the markers and, — the scandal! — barcodes. BYO SLAM and rendering.
Academic papers often use ARToolKit, that’s why it’s mentioned on every corner.
Blood, sweat and opensource.
{kind=link}
I think I need to give my own opinion on all of this. My opinion: I don’t believe in special AR-only gadgets for consumers. But I believe in AR technology itself. Let me explain.
Yes, we’re all waiting for Apple glasses and hope they will ‘revolutionize the game.’ I’m even optimistic about Apple marketers being able to sell them to hipsters who never wore glasses. It’s already happened with Apple Watch. Trendy.
Colorful rims for $69.99 will make all the money again.
Alas, the gadget will go the way Apple Watch did. Yes, we are all wearing them happily, sales are great, but, in essence, they haven’t changed our lives. Just a fashionable accessory that beeps with push notifications, sometimes makes you stand up, and sometimes ‘oh, look how many circles I closed!’
I fear that the same will happen to the glasses. I’ll be glad if I’m wrong.
However, I believe that AR technologies will take root in our life in different ways. They’ll do it quietly, imperceptibly, and not under the guise of ‘life in a new reality.’
As a part of photography — yep. Instagrammers will be ecstatic. As a part of VR entertainment — yes. Gamers will finally be able to live in their helmets. As small useful everyday tools for object recognition, shopping and indoor navigation — yep, yep, and yep.
This is the area I’d be thinking about.
For the consumer, AR will get blurred across a thousand user cases and will stop being something separate, big and magical. It will become simply a part of the experience. We won’t have to come up with UX for AR, because AR will become an element of our UX.
This is the only way AR can become useful. Because in the end, the victory belongs to those who create value and not hype.
That’s it. Thanks for reading.
If you liked the post — share it, say thanks or support me by buying the offline version of it.